
A Machine-Learning Approach for Prediction of Water Contamination Using Latitude, Longitude, and Elevation

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
- Access to these data by the Government can help it shape policies and laws, which would look towards preventing contamination.
- The general public can become aware of the drinkability of the water in their area, which would help them know whether they need water purifiers at their homes or not.
- The study can help in the further analysis and development in the field of water contamination prevention.
2. Related Work
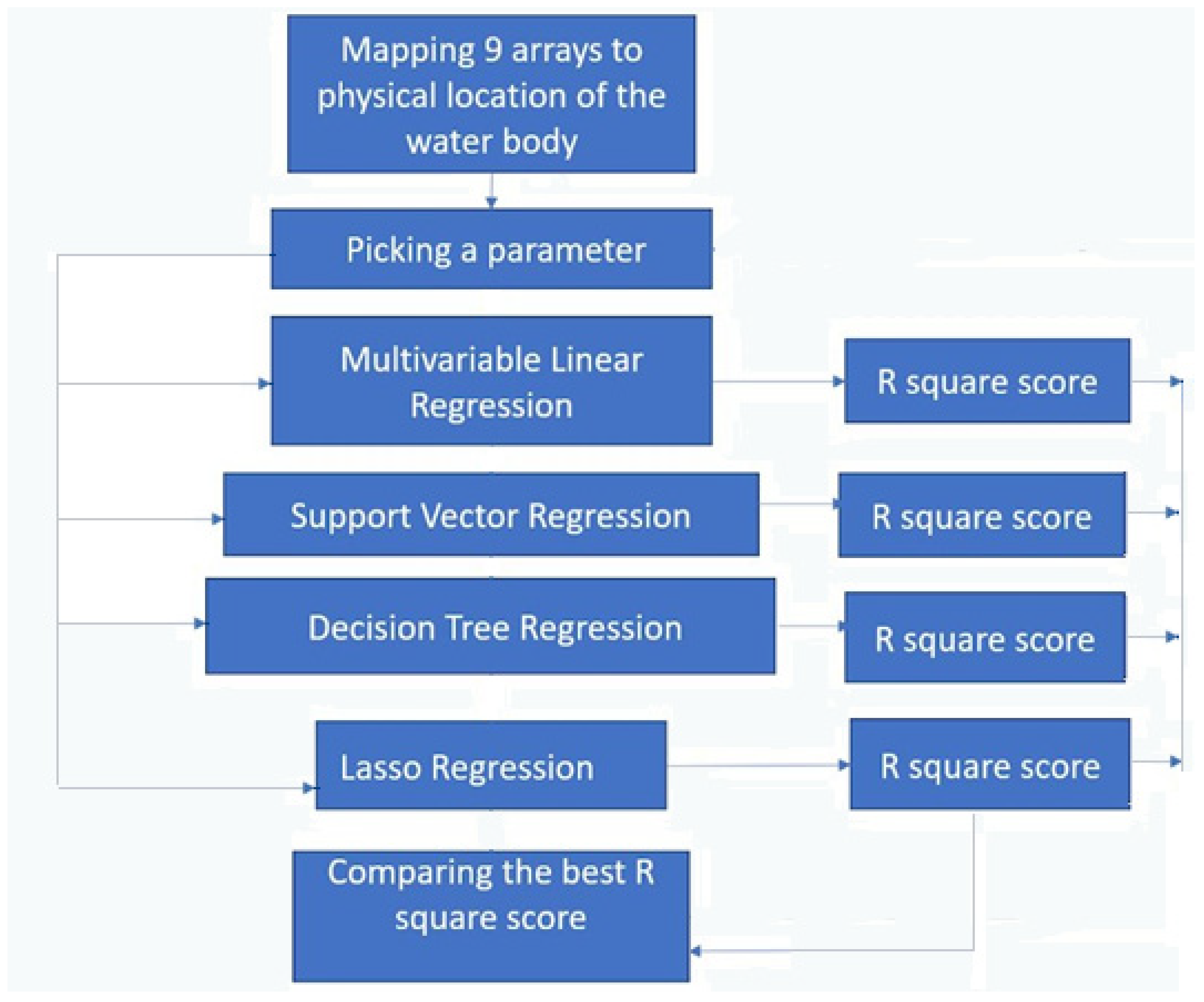
3. Methodology
3.1. Data Acquisition
3.1.1. Temperature
- pH: For an increase in temperature, the ratio of ionization to its molecule increases, hence increasing the toxicity of water by increasing the chemical content.
- Toxicity: A rise in temperature leads to an increase in solubility of compounds, which increases toxicity.
- Metabolic rate: It has been observed that metabolic rates of aquatic plants increase, whereas fishes such as salmon and trout decrease because they prefer colder temperatures. It does not affect the temperature but shows how metabolic rates change with the change in temperature.
- Dissolved oxygen: Increase in temperature results in an increase in solubility of oxygen and other gases. Thus, lakes and streams with lower temperatures can hold more dissolved oxygen than warmer water. As dissolved oxygen increases too much, it increases bacteria and algae, which results in contamination.
3.1.2. pH
- Bedrock and soil composition affect the pH as rocks such as limestone neutralize the acid, whereas rocks such as granite do not affect the pH, resulting in deviation of the pH from the required level of 7.
- Plant growth and organic material in the water body release carbon dioxide when they decompose, which combines with water forms carbonic water and converts the water to slightly acidic.
- Acid rain pollutes the water because they contain nitrogen oxides (NOx) (x could be 2 or 3 depending on if it is dioxide or trioxide) and sulfur dioxide (SO2) along with water vapor, thus increasing the acidity of the water.
- Iron sulfide, a mineral found in and around coal, combines with water to form sulfuric acid, a strong acid; hence, coal mine drainage severely affects the pH of the water.
3.1.3. Chlorides
- Agricultural waste increases the chloride content in water.
- Rocks that contain chloride content.
- Waste water from wastewater treatment plants also has a high amount of chloride content in them.
- The industrial waste also contains high amounts of chloride.
3.1.4. Dissolved Oxygen
3.1.5. Alkalinity
3.1.6. Chemical Oxygen Demand (COD)
3.1.7. Hardness
3.1.8. Turbidity
3.1.9. BOD (Biological Oxygen Demand)
3.1.10. Acidity
3.2. Data Pre-Processing
3.3. Processing
3.4. Algorithms Used
3.4.1. Multivariable Linear Regression
3.4.2. Support Vector Regression
3.4.3. Decision Tree Regression
3.4.4. Lasso Regression
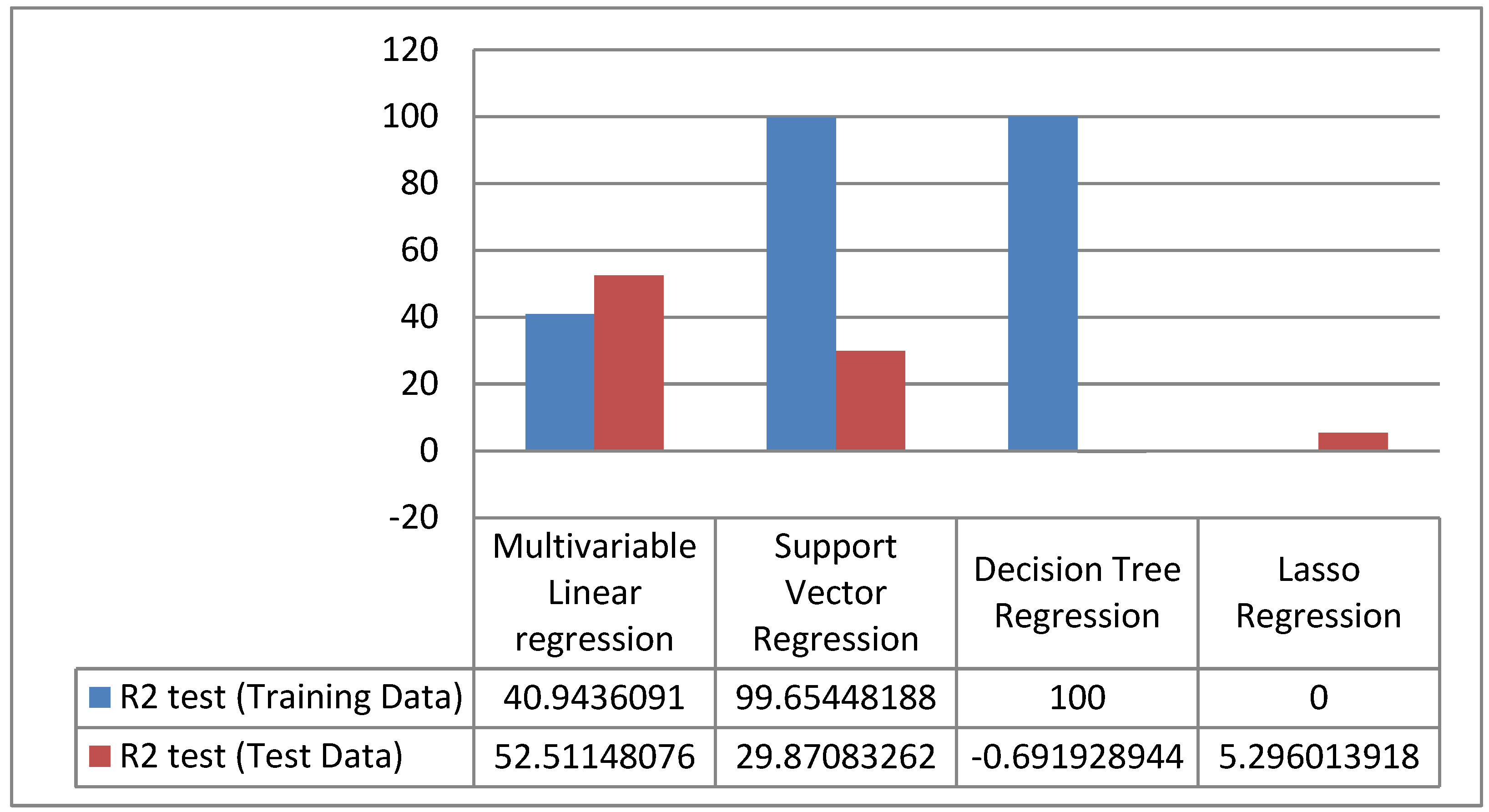
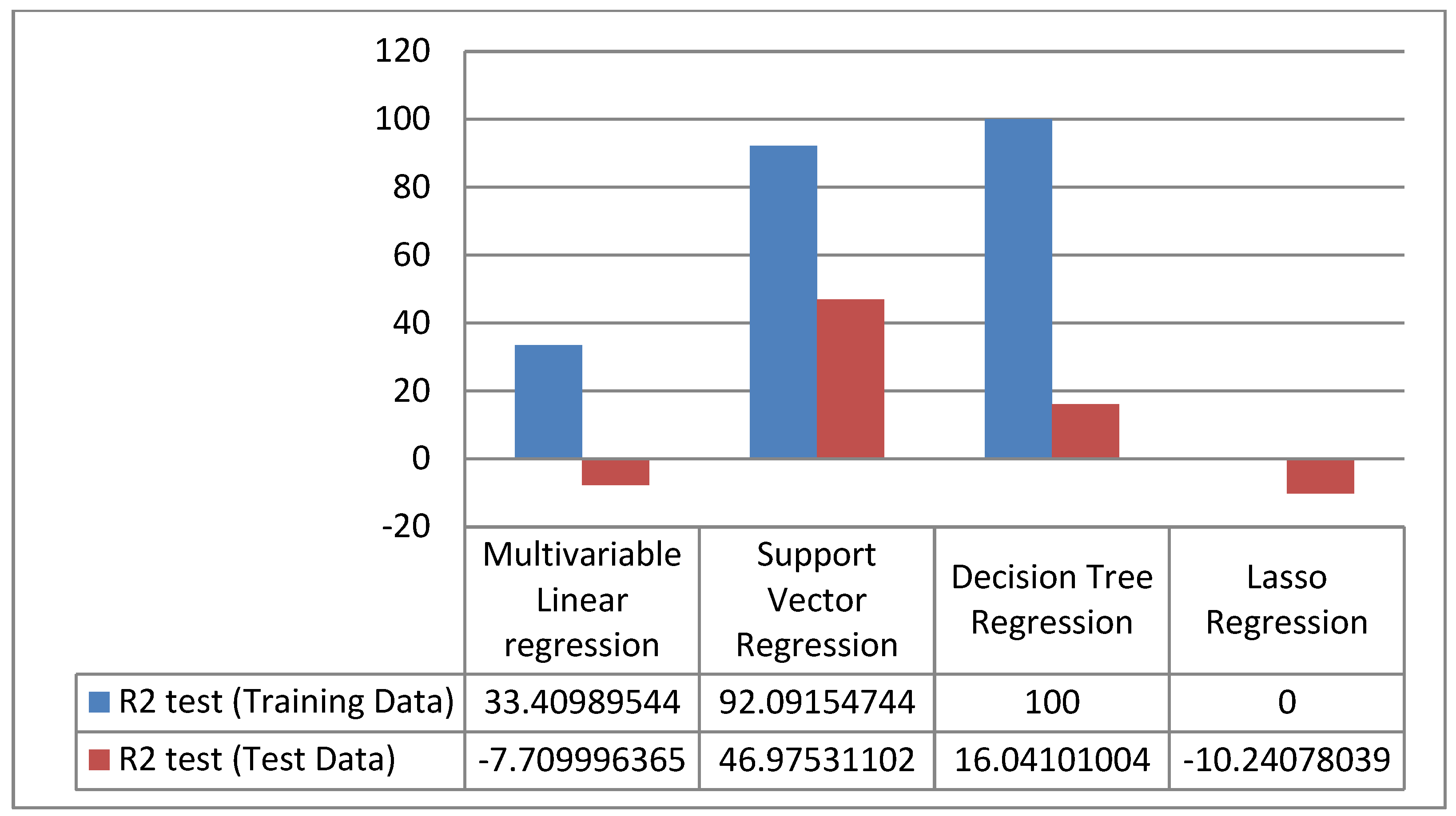
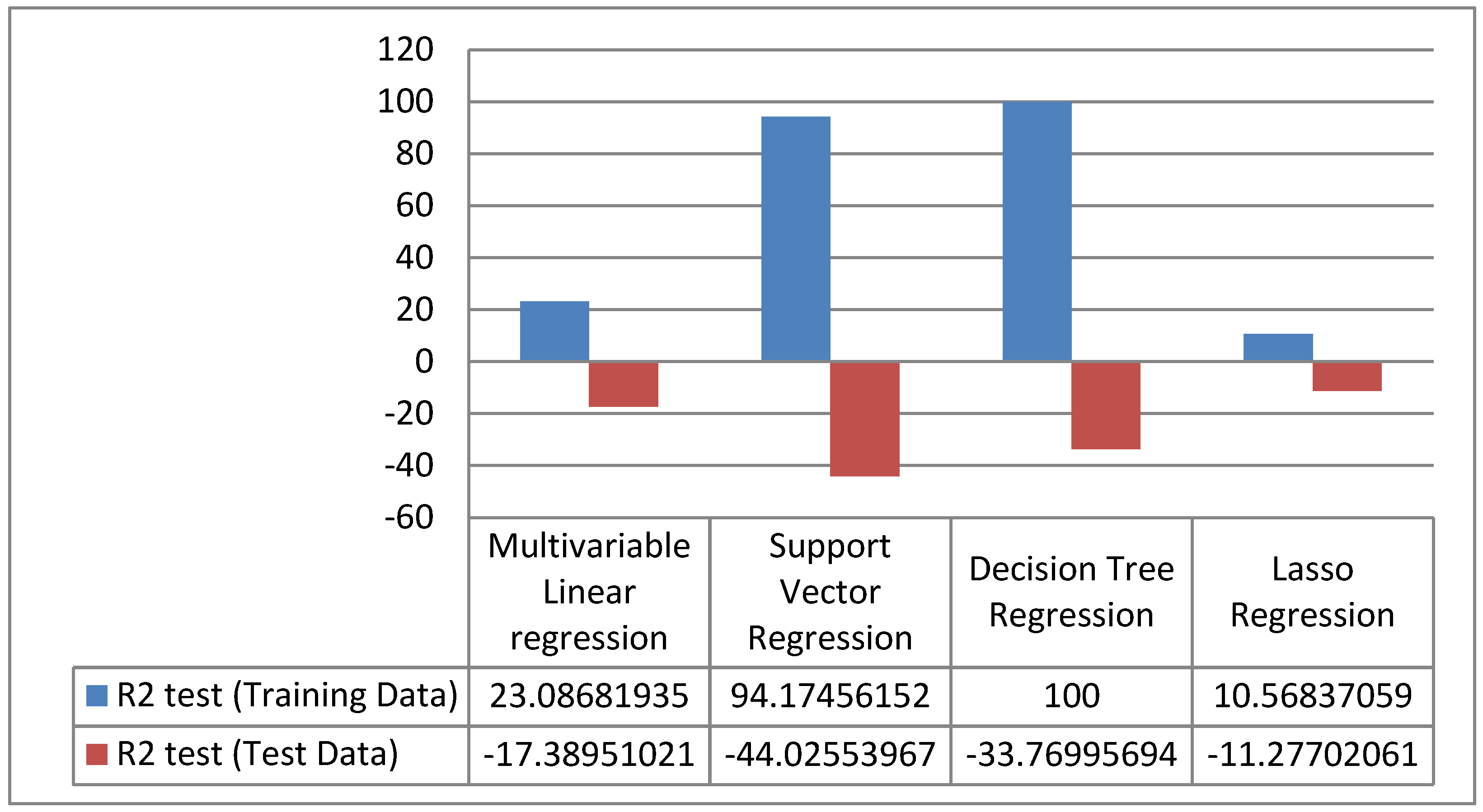
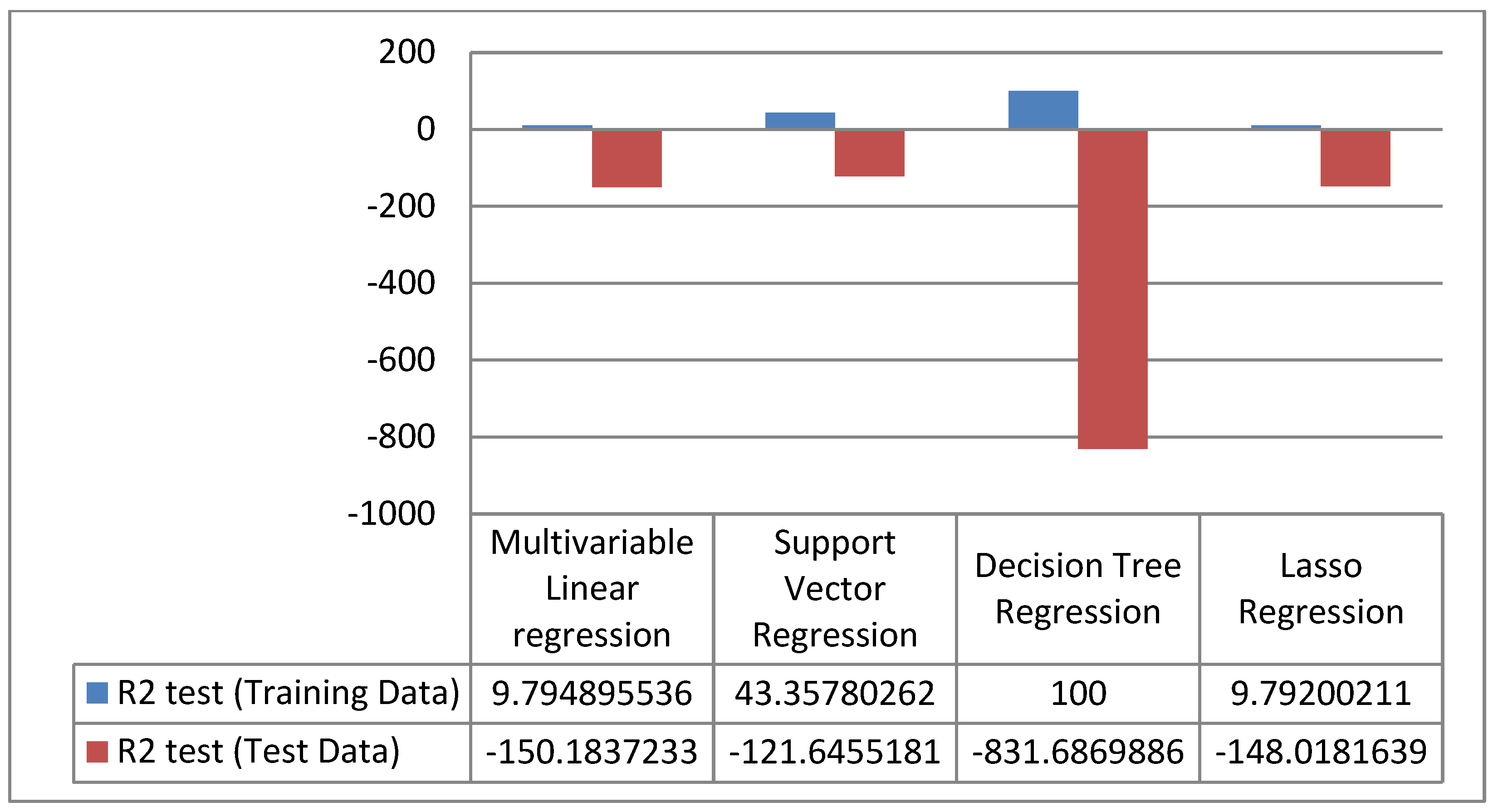
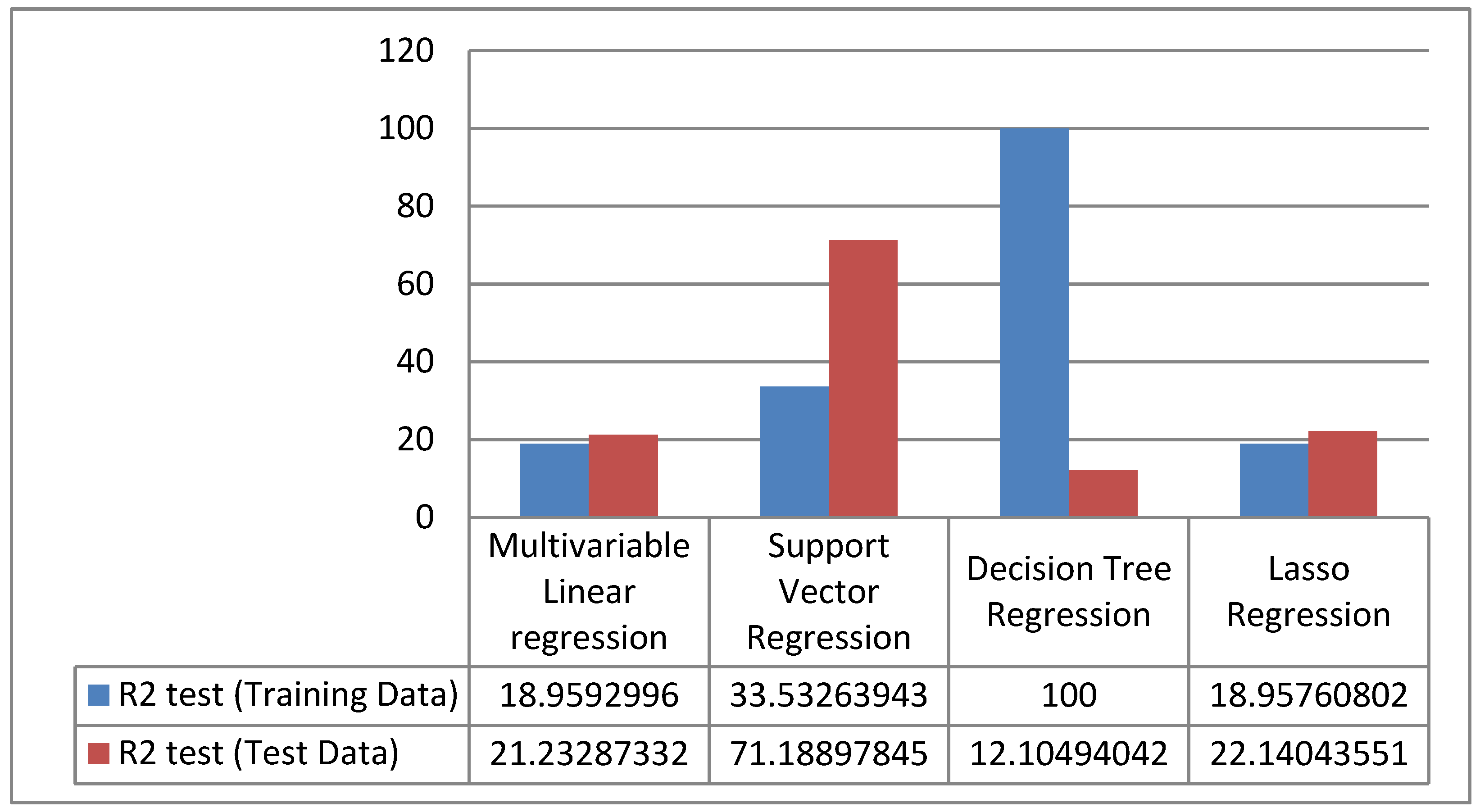
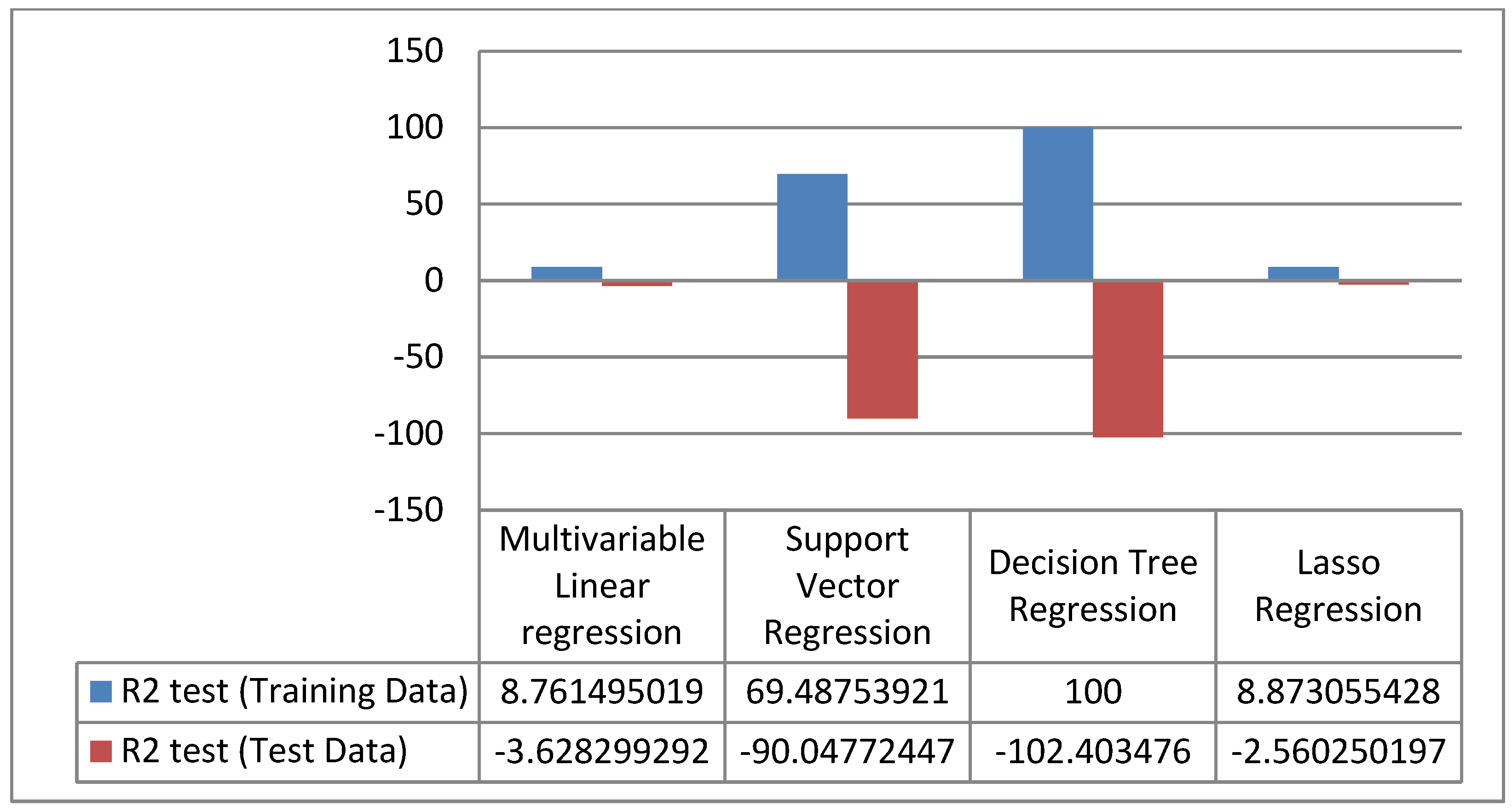
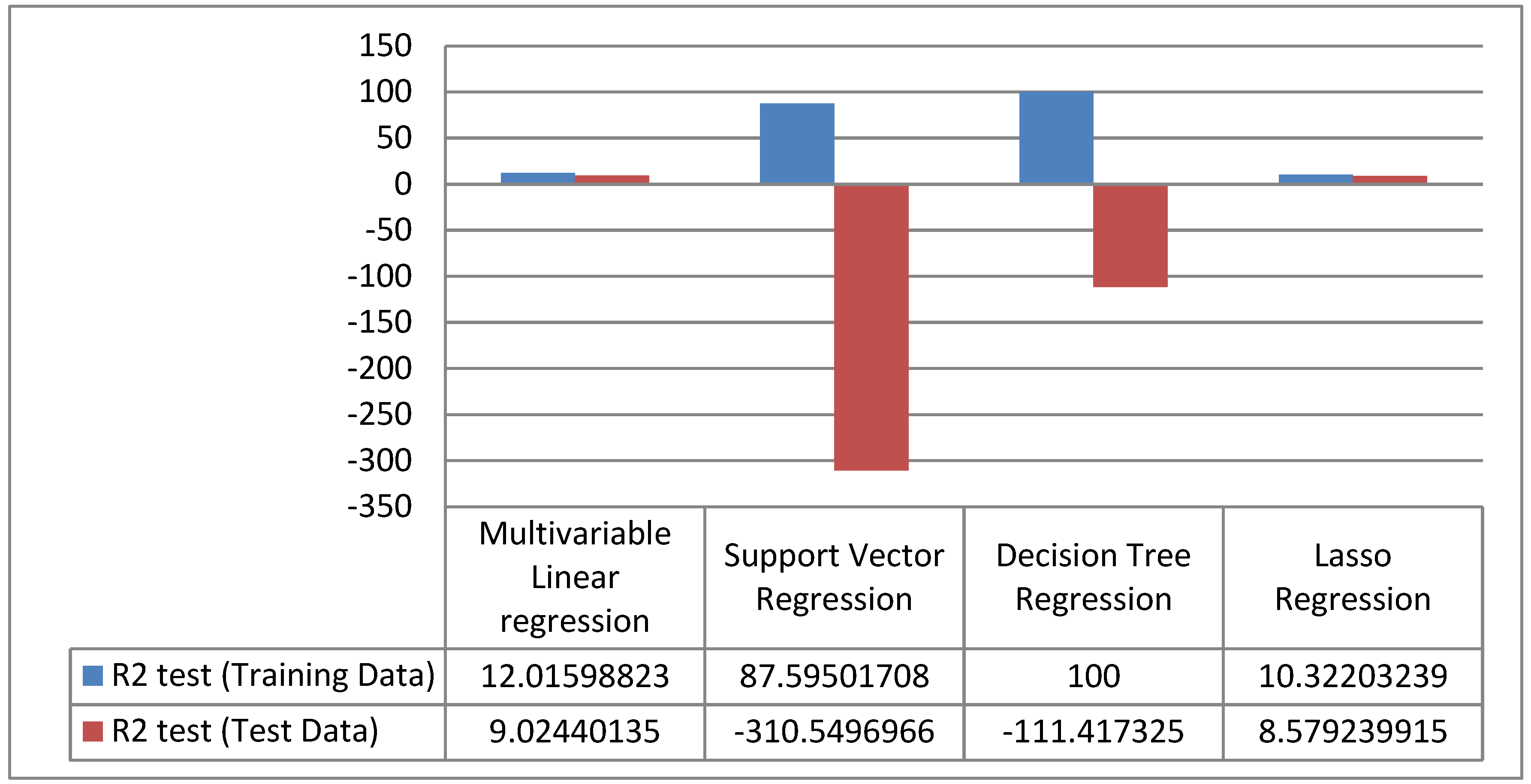
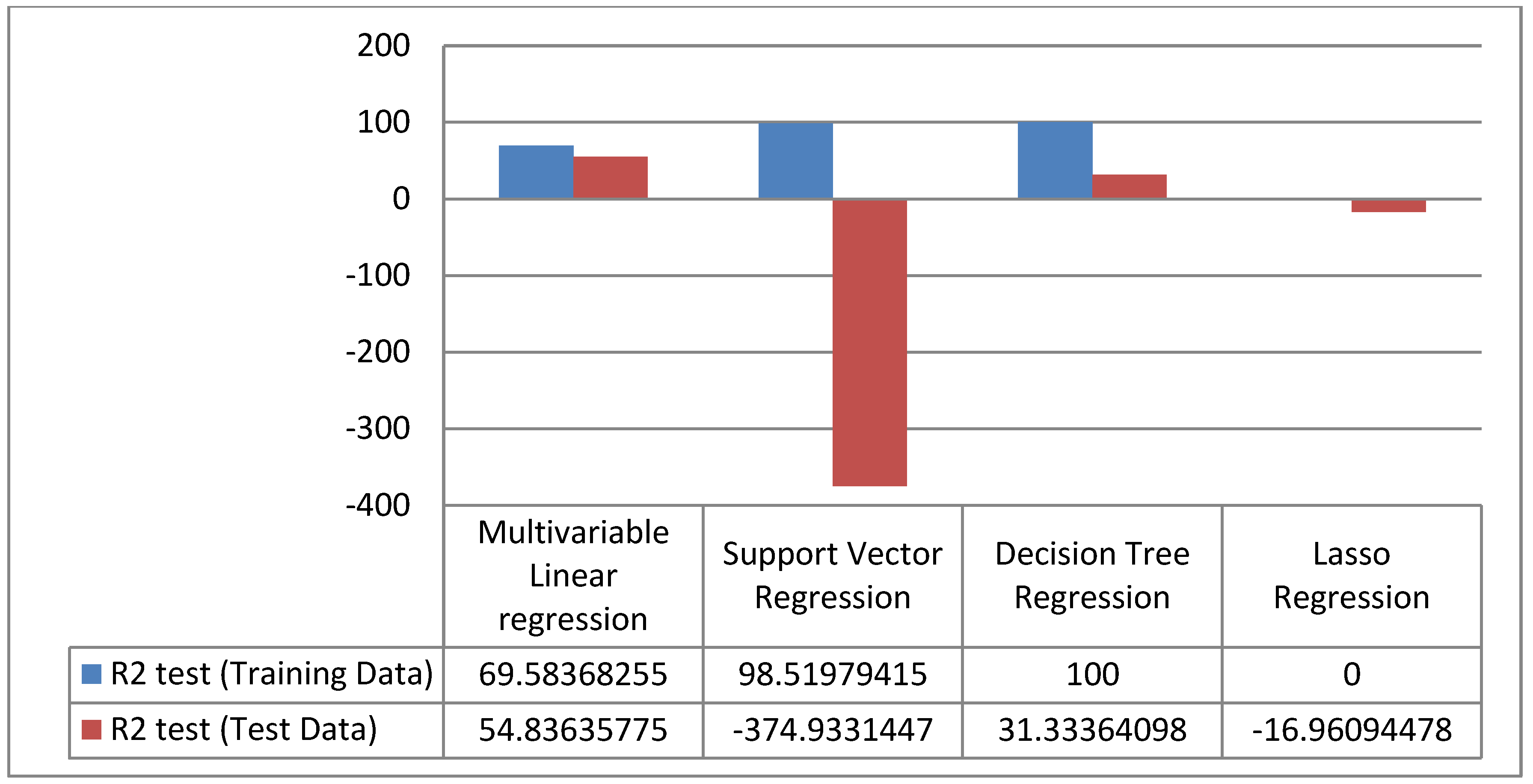
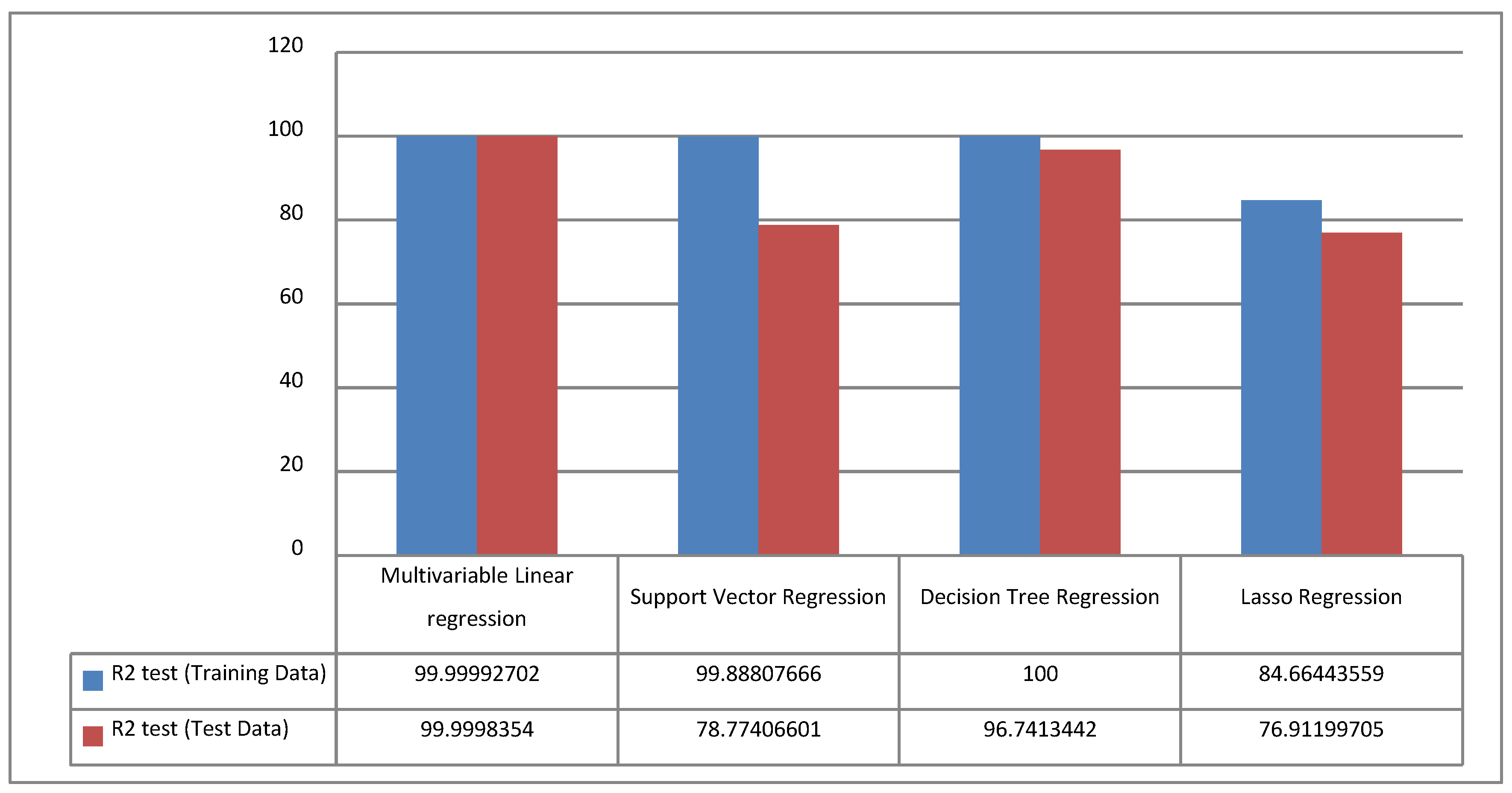
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krishnan, K.S.D. Multiple Linear Regression-Based Water Quality Parameter Modeling to Detect Hexavalent Chromium in Drinking Water. In Proceedings of the 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 22–24 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2434–2439. [Google Scholar]
- Aho, M.I.; Akpen, G.D.; Ekwule, O.R. Predictive regression models of water quality parameters for river Amba in Nasarawa State, Nigeria. Intl. J. Innov. Eng. Sci. Res. 2018, 2, 24–33. [Google Scholar]
- Ahmed, U.; Mumtaz, R.; Anwar, H.; Shah, A.A.; Irfan, R.; García-Nieto, J. Efficient Water Quality Prediction Using Supervised Machine Learning. Water 2019, 11, 2210. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, A.K. The Correlation and Regression Analysis of Physicochemical Parameters of River Water fortheEvaluationofPercentageContributiontoElectricalConductivity, Hindawi. J. Chem. 2018, 2018, 8369613. [Google Scholar] [CrossRef]
- Daud, M.K. Drinking water quality status and contamination in Pakistan. BioMedRes 2017, 2017, 7908183. [Google Scholar] [CrossRef]
- Shafi, U. Surface Water Pollution Detection using Internet of Things. In Proceedings of the 15th International Conference on Smart Cities:Improving Quality of Life Using ICT &IoT(HONET-ICT), Islamabad, Pakistan, 2 August 2019; pp. 92–96. [Google Scholar]
- Pant, R.R. Spatiotemporal variations of hydrogeochemistry and its controlling factors in the Gandaki river basin, Central Himalaya Nepal. Sci. Total. Environ. 2018, 622–623, 770–782. [Google Scholar] [CrossRef]
- Khatunm, M. Phytoplankton assemblage with relation to water quality in Turag River of Bangladesh. Casp. J. Environ. Sci. 2020, 18, 31–45. [Google Scholar]
- Rose-Rodrígue, R. Water and fertilizers use efficiency in two hydroponic systems for tomato production. Hortic. Bras. 2020, 38, 47–52. [Google Scholar] [CrossRef]
- Trombadore, O. Effective Data Convergence, Mapping, and Pollution Categorization of Ghats at Ganga River Front in Varanasi; Springer: Berlin/Heidelberg, Germany, 2020; Volume 27, pp. 15912–15924. [Google Scholar]
- Bapa, G. Evaluation of Physico-chemical characters of Singhia and Budhi rivers in Sunsari and Morang industrial corridor, Nepal. Int. J. Adv. Res. Biol. Sci. 2014, 1, 104–112. [Google Scholar]
- Paudyal, R.; Kang, S.; Sharma, C.; Tripathee, L.; Sillanpää, M. Variations of the Physicochemical Parameters and Metal Levels and Their Risk Assessment in Urbanized Bagmati River, Kathmandu, Nepal. J. Chem. 2016, 2016, 1–13. [Google Scholar] [CrossRef]
- Tripathi, B. Studies on the physicochemical parameters and correlation coefficient of the river Ganga at Holy Place, Allahabad. J. Environ. Sci. Toxicol. Food Technol. 2014, 8, 29–36. [Google Scholar]
- Banerjee, K.; Prasad, R.A. Reference based inter chromosomal similarity based DNA sequence compression algorithm. In Proceedings of the 2017 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 234–238. [Google Scholar]
- Banerjee, K.; Bali, V. Design and Development of Bioinformatics Feature Based DNA Sequence Data Compression Algorithm. EAI Endorsed Trans. Pervasive Health Technol. 2020, 19, 5. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, K.; Prasad, R.A. A new technique in reference based DNA sequence compression algorithm: Enabling partial decompression. In Proceedings of the AIP Conference Proceedings American Institute of Physics, Roorkee, India, 17 February 2015. [Google Scholar]
- Yadav, N.; Banerjee, K.; Bali, V. A Survey on Fatigue Detection of Workers Using Machine Learning. Int. J. E-Health Med. Commun. 2020, 11, 1–8. [Google Scholar] [CrossRef]
- Iwendi, C.; Maddikunta, P.K.R.; Gadekallu, T.R.; Lakshmanna, K.; Bashir, A.K.; Piran, M.J. A metaheuristic optimization approach for energy efficiency in the IoT networks. Softw. Pract. Exp. 2020, 51, 2558–2571. [Google Scholar] [CrossRef]
- Patel, H.; Singh Rajput, D.; Thippa Reddy, G.; Iwendi, C.; Kashif Bashir, A.; Jo, O. A review on classification of imbalanced data for wireless sensor networks. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720916404. [Google Scholar] [CrossRef]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Bashir, A.K.; Noor, F. Realizing an efficientIoMT-assisted patient diet recommendation system through machine learning model. IEEE Access 2020, 8, 28462–28474. [Google Scholar] [CrossRef]
- Iwendi, C.; Jalil, Z.; Javed, A.R.; Reddy, T.; Kaluri, R.; Srivastava, G.; Jo, O. Keysplitwatermark: Zero watermarking algorithm for software protection against cyber-attacks. IEEE Access 2020, 8, 72650–72660. [Google Scholar] [CrossRef]
- Iwendi, C.; Bashir, A.K.; Peshkar, A.; Sujatha, R.; Chatterjee, J.M.; Pasupuleti, S.; Jo, O. COVID-19 patient health prediction using boosted random forest algorithm. Front. Public Health 2020, 8, 357. [Google Scholar] [CrossRef]
- Banerjee, K.; Kumar, S.; Tilak, L.N.; Vashistha, S. Analysis of Groundwater Quality Using GIS-Based Water Quality Index in Noida, GautamBuddh Nagar, Uttar Pradesh (UP), India. In Applications of Artificial Intelligence and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2021; pp. 171–187. [Google Scholar]
- Banerjee, K.; Kumar, M.S.; Tilak, L.N. Delineation of Potential Groundwater Zones using Analytical Hierarchy Process (AHP) for GauthamBuddh Nagar District, Uttar Pradesh, India; Materials Today: Amsterdam, The Netherlands, 2021; Volume 44, pp. 4976–4983. [Google Scholar]
- Kumar, N.; Mishra, B.; Bali, V. A novel approach for blast-induced fly rock prediction based on particle swarm optimization and artificial neural network. In Proceedings of the International Conference on Recent Advancement on Computer and Communication, Paris, France, 22–23 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–27. [Google Scholar]
- Malhotra, S.; Bali, V.; Paliwal, K.K. Genetic programming and K-nearest neighbour classifier based intrusion detection model. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science & Engineering–Confluence, Noida, India, 12–13 January 2017; pp. 42–46. [Google Scholar] [CrossRef]
- Frank, J. Public Drinking Water Contamination and Birth Outcomes. Am. J. Epidemiol. 1995, 141, 850–862. [Google Scholar]
- Osmani, S.A. An Integrated Approach of Machine Algorithms with Multi-Objective Optimization in Performance Analysis of Event Detection; Springer: Warsaw, Poland, 2020. [Google Scholar]
- Hart, B.W. Sensor Placement in Municipal Water Networks with Temporal Integer Programming Models. J. Water Resour. Plan. Manag. 2006, 132, 1943–5452. [Google Scholar]
- Blackburn, B.G. Surveillance for Waterborne-Disease Outbreaks Associated with Drinking Water–United States, 2001–2002; Division of Healthcare Quality Promotion, National Center for Infectious Diseases, CDC: Singapore, 2004; pp. 23–45.
- Brunkard, J.M. Surveillance for Waterborne Disease Outbreaks Associated with Drinking Water–United States, 2007–2008; Division of Healthcare Quality Promotion, National Center for Infectious Diseases, CDC: Singapore, 2011; pp. 38–68.
- CANARY, Sandia National Laboratoris. Available online: https://software.sandia.gov/trac/canary (accessed on 21 January 2022).
- Deb, K. A Fast and Elitist Multi-objective Genetic Algorithm. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Cristo, C. Pollution Source Identification of Accidental Contamination in Water Distribution Networks. J. Water Resour. Plan. Manag. 2008, 134, 1943–5452. [Google Scholar] [CrossRef]
- Hasan, J.; States, S.; Deininger, R. Safeguarding the Security of Public Water Supplies Using Early Warning Systems: A Brief Review. J. Contemp. Water Res. Educ. 2009, 129, 27–33. [Google Scholar] [CrossRef] [Green Version]
- Smitha, K. Contaminant classification using cosine distances based on multiple conventional sensors. Environ. Sci. Process. Impacts 2015, 17, 581. [Google Scholar]
- Liu, S.; Che, H.; Smith, K.; Chen, L. Contamination event detection using multiple types of conventional water quality sensors in source water. Environ. Sci. Process. Impacts 2014, 16, 2028–2038. [Google Scholar] [CrossRef]
- Liu, S.; Butler, D.; Memon, F.A.; Makropoulos, C.; Avery, L.; Jefferson, B. Impacts of residence time during storage on potential of water saving for grey water recycling system. Water Res. 2010, 44, 267–277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Li, R.; Smith, K.; Che, H. Why conventional detection methods fail in identifying the existence of contamination events. Water Res. 2016, 93, 222–229. [Google Scholar] [CrossRef]
- Liu, S.; Smith, K.; Che, H. A multivariate based event detection method and performance comparison with two baseline methods. Water Res. 2015, 80, 109–118. [Google Scholar] [CrossRef]
- Masky, S. Treatment of Precipitation Uncertainty in Rainfall-Run Off Modelling: A Fuzzy Set Approach; Elsevier Science: Amsterdam, The Netherlands, 2004; Volume 27, pp. 889–898. [Google Scholar]
- Maskey, S. Reatment of precipitation uncertainty in rainfall-runoff modelling: A fuzzy set approach. Adv. Water Res. 2004, 27, 889–998. [Google Scholar] [CrossRef]
- Leite, C. Toxic impacts of rutile titanium dioxide in Mytilusgalloprovincialis exposed to warming conditions. Chemosphere 2020, 252, 126563. [Google Scholar] [CrossRef]
- Ali, S. Health Effects from Exposure to Sulphates and Chlorides in Drinking Water. Pak. Med. Health Sci. 2012, 6, 648–652. [Google Scholar]
- Yang, W. Defluoridation of drinking water by combined electrocoagulation: Effects of the molar ratio of alkalinity and fluoride to Al(III). Chemosphere 2008, 74, 1391–1395. [Google Scholar] [CrossRef]
- Lou, J. Influence of alkalinity, hardness and dissolved solids on drinking water taste: A case study of consumer satisfaction. J. Environ. Manag. 2007, 82, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Ali, J. Chemical analysis of air and water, Bioassays. Adv. Methods Appl. 2018, 4, 21–39. [Google Scholar]
- Frimmel, F.H. Sum Parameters: Potential and Limitations. Treatise Water Sci. 2010, 3, 192146. [Google Scholar]
- Hardness in Drinking-Water Background Document for Development of WHO Guidelines for Drinking-Water Quality. Available online: https://apps.who.int/iris/handle/10665/70168 (accessed on 21 January 2020).
- Schroeder, H.A. Relations between hardness of water and death rates from certain chronic and degenerative diseases in the United States. J. Chronic Dis. 1960, 12, 586–591. [Google Scholar] [CrossRef]
- Wasana, H.M.S. Drinking water quality and chronic kidney disease of unknown etiology (CKDu): Synergic effects of fluoride, cadmium, and hardness of water. Environ. Geo. Health 2016, 38, 157–168. [Google Scholar] [CrossRef]
- Paaijmans, K.P. The Effect of Water Turbidity on the Near-Surface Water Temperature of Larval Habitats of The Malaria Mosquito Anopheles Gambiae; Springer: Berlin/Heidelberg, Germany, 2007; Volume 52, pp. 747–753. [Google Scholar]
- Smith, D.G. Turbidity Suspended Sediment, and Water Clarity: A Review; Wiley Online Library: Hoboken, NJ, USA, 2001; Volume 37, pp. 1085–1101. [Google Scholar]
- Draper, N.R. The Box-Wetz Criterion Versus R2. J. R. Stat. Soc. 1984, 147, 100–103. [Google Scholar]
- Chandra, D.S. Estimation of water quality index by weighted arithmetic water quality index method: A model study. Int. J. Civ. Eng. 2017, 8, 1215–1222. [Google Scholar]
- Reddy, T. Characterisation of the primary heat replacement element event for a horizontal electric water heater. In Proceedings of the IEEE 2020 International SAUPEC/RobMech/PRASA Conference, Cape Town, South Africa, 29–30 January 2020. [Google Scholar]
- Quan, Q. Research on water temperature prediction based on improved support vector regression. New Trends Brain-Comput. Interface 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Xiang, Z. An application of contingent valuation and decision tree analysis to water quality improvements. Mar. Pollut. Bull. 2007, 55, 591–602. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
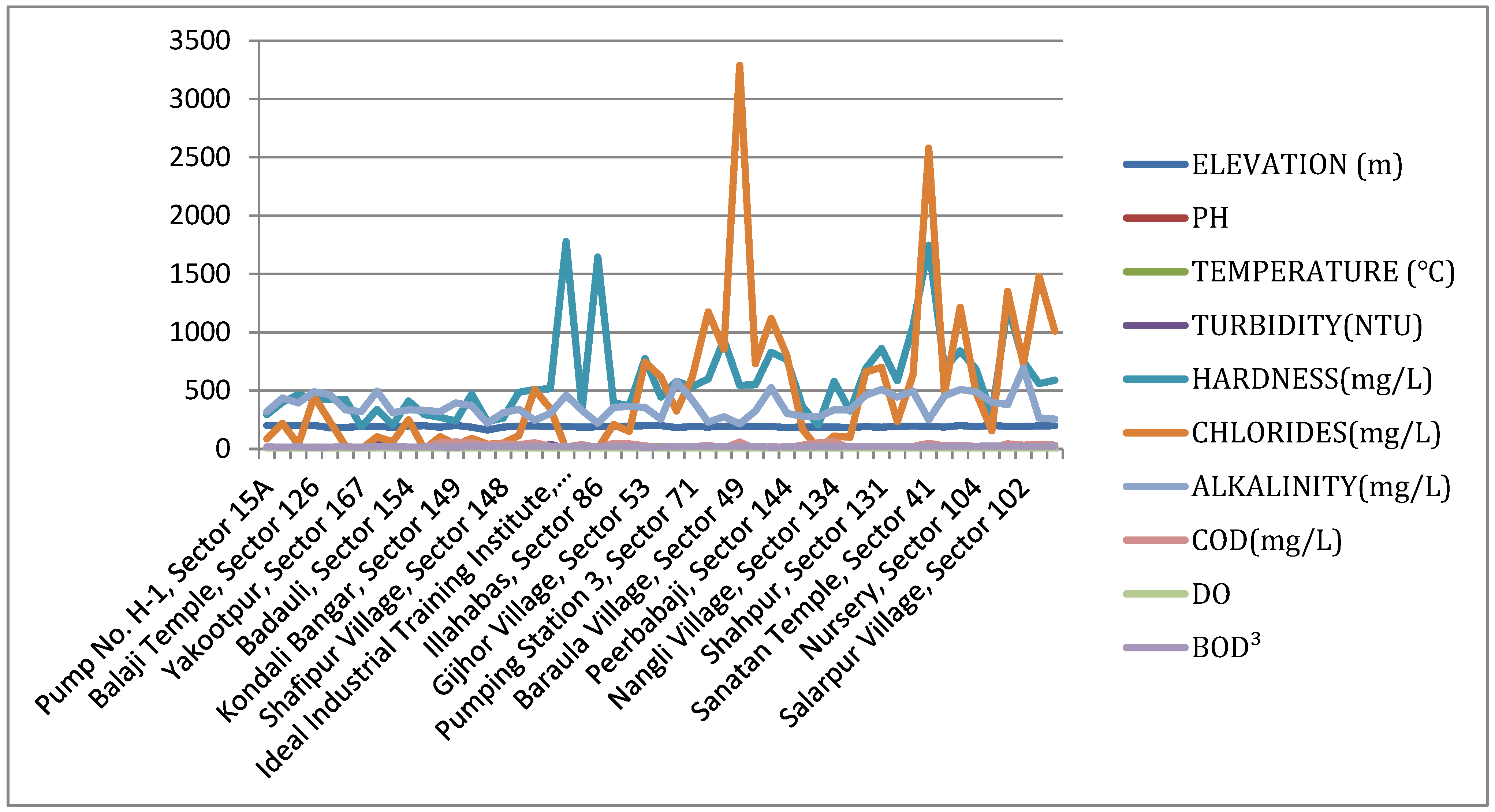
| Location | Latitude (N) | Longitude (E) | Elevation (m) | pH | Temperature (°C) | Turbidity (NTU) | Hardness (mg/L) | Chlorides (mg/L) | Alkalinity (mg/L) | COD (mg/L) | DO | BOD3 | Acidity | Chlorine |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pump No. H-1, Sector 15A | 28°34′34.7″ | 77°18′29.9″ | 203 | 8.74 | 15 | 9 | 295 | 84.97 | 319 | 16 | 6.4 | 18 | NIL | NIL |
| AsagarpurJagirVilage, Sector 128 | 28°31′17″ | 77°20′58.2″ | 201 | 8.2 | 11.3 | 0 | 400 | 219.93 | 435 | 10.66 | 7.6 | 15.3 | NIL | NIL |
| Hindustan Petroleum, Near Jaypee Hospital | 28°30′20.9″ | 77°21′56.2″ | 198 | 8 | 16.2 | 0 | 465 | 34.98 | 395 | 10.66 | 6.8 | 18 | NIL | NIL |
| Balaji Temple, Sector 126 | 28°32′11″ | 77°20′22.9″ | 202 | 8.35 | 15.5 | 0 | 430 | 449.86 | 490 | 10.66 | 8.4 | 14.4 | NIL | NIL |
| Ankit Nursery, Sector 131 | 28°30′46.27″ | 77°21′09.12″ | 181 | 8.04 | 13.9 | 1 | 425 | 234.92 | 465 | 5.33 | 5.6 | 16.2 | NIL | NIL |
| Green Beauty Farm, Sector 135 | 28°28′58.74″ | 77°22′59.48″ | 185 | 8.36 | 14.3 | 3 | 425 | 24.99 | 335 | 10.66 | 6.8 | 18 | NIL | NIL |
| Yakootpur, Sector 167 | 28°28′32.94″ | 77°25′2.11″ | 192 | 8.68 | 14.6 | 3 | 190 | 0 | 320 | 10.66 | 6 | 15.3 | NIL | NIL |
| Gulavali, Sector 162 | 28°28′5.37″ | 77°26′5″ | 193 | 8.2 | 14.3 | 56 | 340 | 104 | 495 | 5.33 | 5.6 | 19.8 | NIL | NIL |
| Jhatta Village, Sector 159 | 28°27′52.09″ | 77°26′54.14″ | 186 | 8.6 | 14.3 | 4 | 205 | 59.98 | 310 | 16 | 5.6 | 19.8 | NIL | NIL |
| Badauli, Sector 154 | 28°27′20.43″ | 77°27′39.94″ | 195 | 8.23 | 13.6 | 2 | 410 | 250 | 335 | 16 | 6.4 | 17.1 | NIL | NIL |
| KambuxpurDerin Village, Sector 155 | 28°26′40.84″ | 77°27′19.39″ | 199 | 8.63 | 13.7 | 2 | 295 | 0 | 330 | 16 | 7.6 | 16.2 | NIL | NIL |
| GujjarDerin, Kambuxpur, Sector 155A | 28°27′0.77″ | 77°27′11.08″ | 186 | 8.51 | 13.3 | 3 | 270 | 104.96 | 320 | 53.33 | 6.4 | 16.2 | NIL | NIL |
| KondaliBangar, Sector 149 | 28°26′17.01″ | 77°28′40.27″ | 201 | 8.33 | 13.7 | 3 | 240 | 34.98 | 395 | 58.66 | 8 | 14.4 | NIL | NIL |
| GarhiSamastpur, Sector 150 | 28°25′46.9″ | 77°28′29.85″ | 186 | 8.06 | 14.2 | 5 | 470 | 89.97 | 370 | 53.33 | 3.2 | 26.1 | NIL | NIL |
| Momnathal, Sector 150 | 28°36′33.69″ | 77°21′36.24″ | 163 | 8.90 | 17.4 | 3 | 235 | 39.98 | 220 | 32 | 6.4 | 18.9 | NIL | NIL |
| Shafipur Village, Sector 148 | 28°26′51.99″ | 77°29′17.81″ | 188 | 7.95 | 18.4 | 17 | 265 | 49.98 | 310 | 42.6 | 5.6 | 23.4 | NIL | NIL |
| MohiyapurVillage, Sector 163 | 28°28′42.06″ | 77°26′0.61″ | 196 | 7.57 | 18.1 | 2 | 485 | 114.96 | 340 | 37.33 | 5.6 | 21.6 | NIL | NIL |
| Nalgadha, Sector 145 | 28°28′56.25″ | 77°26′24.5″ | 197 | 7.87 | 17.4 | 2 | 510 | 509.84 | 245 | 53.33 | 6.8 | 19.8 | NIL | NIL |
| Ideal Industrial Training Institute, Sector 143 | 28°29′40.35″ | 77°25′31.13″ | 189 | 7.52 | 16.5 | 38 | 515 | 344.89 | 305 | 21.33 | 4.8 | 23.4 | NIL | NIL |
| Shahdara, Sector 141 | 28°30′17.25″ | 77°25′03.87″ | 191 | 7.1 | 16.9 | 4 | 1780 | 0 | 460 | 16 | 6.4 | 23.4 | NIL | NIL |
| Hindon Flood Plain, Kulesara, Sector 140 | 28°30′43.61″ | 77°25′47.52″ | 188 | 8.27 | 15.6 | 6 | 335 | 30 | 330 | 37.33 | 6.8 | 18 | NIL | NIL |
| Allahabad, Sector 86 | 28°31′16.56″ | 77°24′33.91″ | 189 | 7.79 | 16.1 | 5 | 1645 | 0 | 220 | 10.66 | 6.8 | 20.7 | NIL | NIL |
| SaiDham Colony, Sector 88 | 28°32′09.68″ | 77°25′36.11″ | 194 | 7.94 | 15.4 | 1 | 395 | 210 | 355 | 48 | 6.8 | 19.8 | NIL | NIL |
| Kakrala Village, Sector 80 | 28°33′03.11″ | 77°24′38.26″ | 196 | 8.11 | 15.8 | 9 | 370 | 150 | 365 | 42.66 | 6 | 19.8 | NIL | NIL |
| Gijhor Village, Sector 53 | 28°35′24.07″ | 77°21′47.86″ | 198 | 7.54 | 18.6 | 1 | 775 | 744.77 | 355 | 26.66 | 8.4 | 15.3 | NIL | NIL |
| Sarfabad, Sector 73 | 28°35′20.83″ | 77°23′08.45″ | 200 | 8.28 | 17.7 | 1 | 445 | 619.81 | 255 | 10.66 | 8 | 17.1 | NIL | NIL |
| Sorkha Village, Sector 118 | 28°34′49.64″ | 77°24′22.11″ | 183 | 7.67 | 17.8 | 19 | 580 | 324.9 | 580 | 21.33 | 6.4 | 18.9 | NIL | NIL |
| Pumping Station 3, Sector 71 | 28°35′35.91″ | 77°22′33.01″ | 193 | 7.6 | 18.8 | 1 | 535 | 614.81 | 420 | 16 | 5.2 | 22.5 | NIL | NIL |
| Pump House, Sector 122 | 28°35′39.79″ | 77°23′21.22″ | 187 | 7.65 | 18.1 | 0 | 600 | 1174.64 | 230 | 32 | 6 | 20.7 | NIL | NIL |
| 19, Block H, Sector 116 | 28°34′08.65″ | 77°23′45.80″ | 194 | 7.97 | 18.6 | 1 | 935 | 854.73 | 275 | 5.33 | 6 | 21.6 | NIL | NIL |
| Baraula Village, Sector 49 | 28°33′59.25″ | 77°22′12.96″ | 194 | 7.54 | 18.7 | 21 | 545 | 3288.98 | 215 | 58.66 | 6.4 | 19.8 | NIL | NIL |
| Pumping Station, Sector 35 | 28°34′50.46″ | 77°21′11.94″ | 193 | 7.83 | 17.5 | 1 | 550 | 729.77 | 325 | 0 | 6.8 | 20.7 | NIL | NIL |
| Pumping Station 3, Sector 34 | 28°35′07.80″ | 77°21′23.59″ | 192 | 7.58 | 17.3 | 6 | 830 | 1119.65 | 525 | 21.33 | 8 | 15.3 | NIL | NIL |
| Peerbabaji, Sector 144 | 28°29′26.73″ | 77°26′02.80″ | 183 | 8.45 | 17.3 | 20 | 765 | 799.75 | 305 | 10.66 | 6.8 | 18 | NIL | NIL |
| Dallupura Village, Sector 164 | 28°28′57.49″ | 77°25′47.42″ | 189 | 8.65 | 16.6 | 0 | 360 | 164.95 | 280 | 32 | 8 | 17.1 | NIL | NIL |
| Dostpur, Mangrauli, Sector 167 | 28°29′01.19″ | 77°24′57.37″ | 186 | 8.78 | 16.6 | 50 | 205 | 0 | 275 | 53.33 | 6.4 | 19.8 | NIL | NIL |
| Nangli Village, Sector 134 | 28°29′52.94″ | 77°22′53.76″ | 188 | 8.55 | 16.7 | 0 | 580 | 109.97 | 335 | 64 | 7.2 | 18 | NIL | NIL |
| Bakhtawarpur, Sector 127 | 28°32′03.14″ | 77°21′13.73″ | 185 | 8.31 | 14.1 | 6 | 325 | 99.97 | 335 | 5.33 | 6 | 20.7 | NIL | NIL |
| Sultanpur Village, sector 128 | 28°31′17.97″ | 77°22′06.05″ | 190 | 7.75 | 16.7 | 0 | 690 | 659.8 | 460 | 10.66 | 5.6 | 20.7 | NIL | NIL |
| Shahpur, Sector 131 | 28°30′56.37″ | 77°22′04.54″ | 186 | 7.91 | 15.1 | 0 | 860 | 699.78 | 510 | 16 | 6 | 19.8 | NIL | NIL |
| Sadarpur, Sector 45 | 28°33′02.93″ | 77°21′02.22″ | 194 | 8.01 | 13.5 | 7 | 585 | 234.93 | 445 | 0 | 5.2 | 21.6 | NIL | NIL |
| Chhalera, Sector 44 | 28°33′02.49″ | 77°21′02.57″ | 195 | 7.78 | 16.0 | 0 | 1055 | 634.8 | 495 | 21.33 | 7.2 | 16.2 | NIL | NIL |
| Sanatan Temple, Sector 41 | 28°33′53.91″ | 77°21′36.79″ | 194 | 7.97 | 16.3 | 1 | 1745 | 2579.2 | 250 | 48 | 3.6 | 20.7 | NIL | NIL |
| Shiv Mandir, Sector 31 | 28°34′37.29″ | 77°20′48.62″ | 187 | 7.74 | 16.5 | 0 | 695 | 479.85 | 455 | 26.66 | 6 | 21.6 | NIL | NIL |
| NaglaCharanDass, Noida Phase-2 | 28°32′25.47″ | 77°24′25.02″ | 200 | 7.95 | 16.3 | 4 | 840 | 1214.62 | 510 | 32 | 6 | 21.6 | NIL | NIL |
| Nursery, Sector 104 | 28°32′13.48″ | 77°21′54.55″ | 190 | 7.85 | 16.4 | 1 | 685 | 484.85 | 490 | 21.33 | 4.4 | 23.4 | NIL | NIL |
| Pumping Station, Sector 80 | 28°33′15.36″ | 77°24′23.03″ | 201 | 8.12 | 17.4 | 0 | 290 | 154.95 | 400 | 10.66 | 4.4 | 25.2 | NIL | NIL |
| Shiv Mandir, Sector 93 | 28°31′35.64″ | 77°22′35.64″ | 192 | 7.80 | 17.3 | 1 | 1230 | 1349.58 | 380 | 42.66 | 5.2 | 22.5 | NIL | NIL |
| Salarpur Village, Sector 102 | 28°32′50.20″ | 77°22′56.28″ | 192 | 7.48 | 18.0 | 0 | 750 | 729.77 | 695 | 32 | 4.8 | 23.4 | NIL | NIL |
| GarhiChaukhandi, sector 121 | 28°35′58.99″ | 77°23′41.18″ | 197 | 8.01 | 17.2 | 0 | 560 | 1479.54 | 265 | 37.33 | 5.2 | 21.6 | NIL | NIL |
| Pumping Station, Block-G, Sector 63 | 28°35′58.94″ | 77°23′41.32″ | 199 | 7.92 | 17.7 | 0 | 590 | 1009.69 | 255 | 32 | 4.4 | 24.3 | NIL | NIL |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banerjee, K.; Bali, V.; Nawaz, N.; Bali, S.; Mathur, S.; Mishra, R.K.; Rani, S. A Machine-Learning Approach for Prediction of Water Contamination Using Latitude, Longitude, and Elevation. Water 2022, 14, 728. https://doi.org/10.3390/w14050728
Banerjee K, Bali V, Nawaz N, Bali S, Mathur S, Mishra RK, Rani S. A Machine-Learning Approach for Prediction of Water Contamination Using Latitude, Longitude, and Elevation. Water. 2022; 14(5):728. https://doi.org/10.3390/w14050728
Chicago/Turabian StyleBanerjee, Kakoli, Vikram Bali, Nishad Nawaz, Shivani Bali, Sonali Mathur, Ram Krishn Mishra, and Sita Rani. 2022. "A Machine-Learning Approach for Prediction of Water Contamination Using Latitude, Longitude, and Elevation" Water 14, no. 5: 728. https://doi.org/10.3390/w14050728