
Applying the C-Factor of the RUSLE Model to Improve the Prediction of Suspended Sediment Concentration Using Smart Data-Driven Models

Abstract
:1. Introduction
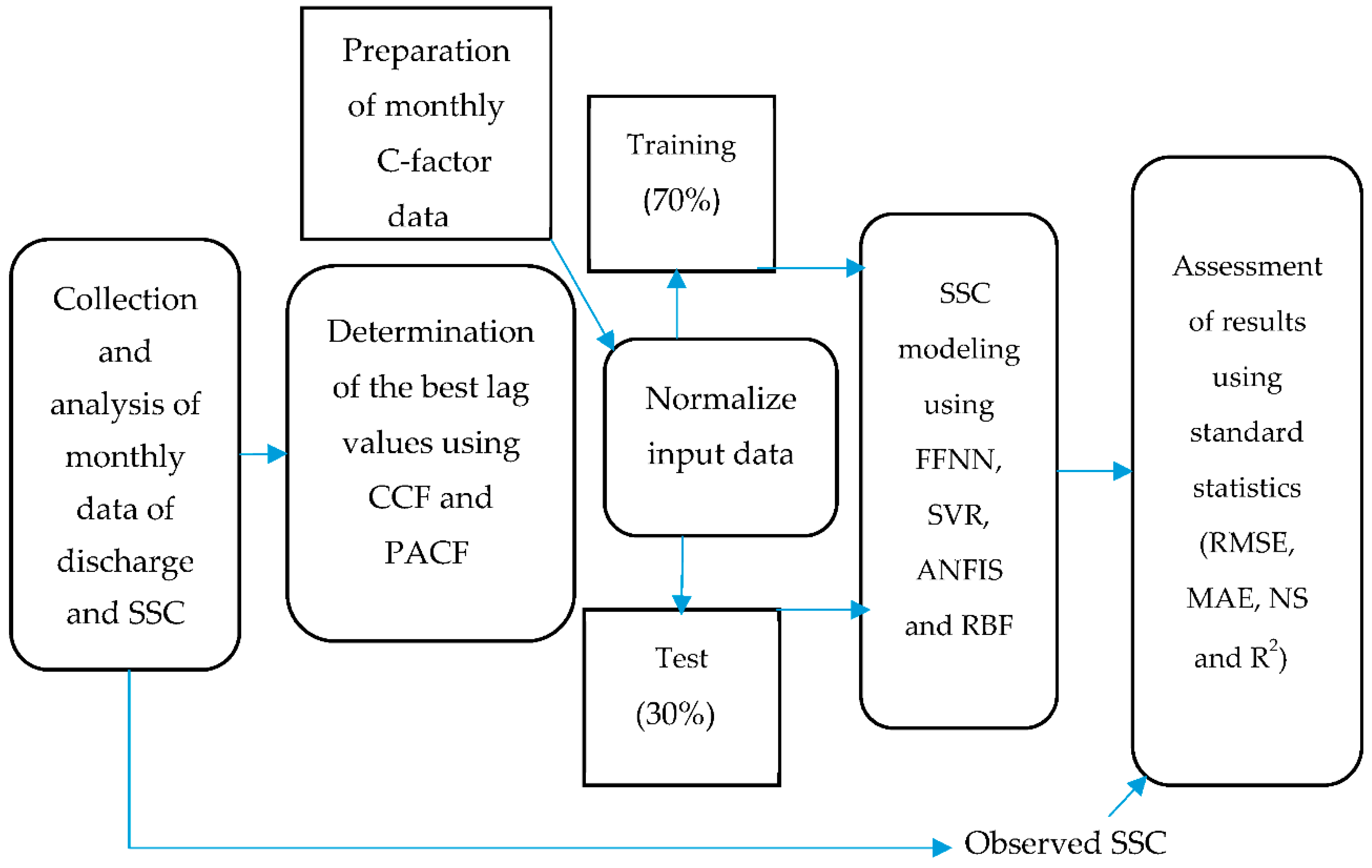
2. Materials and Methods
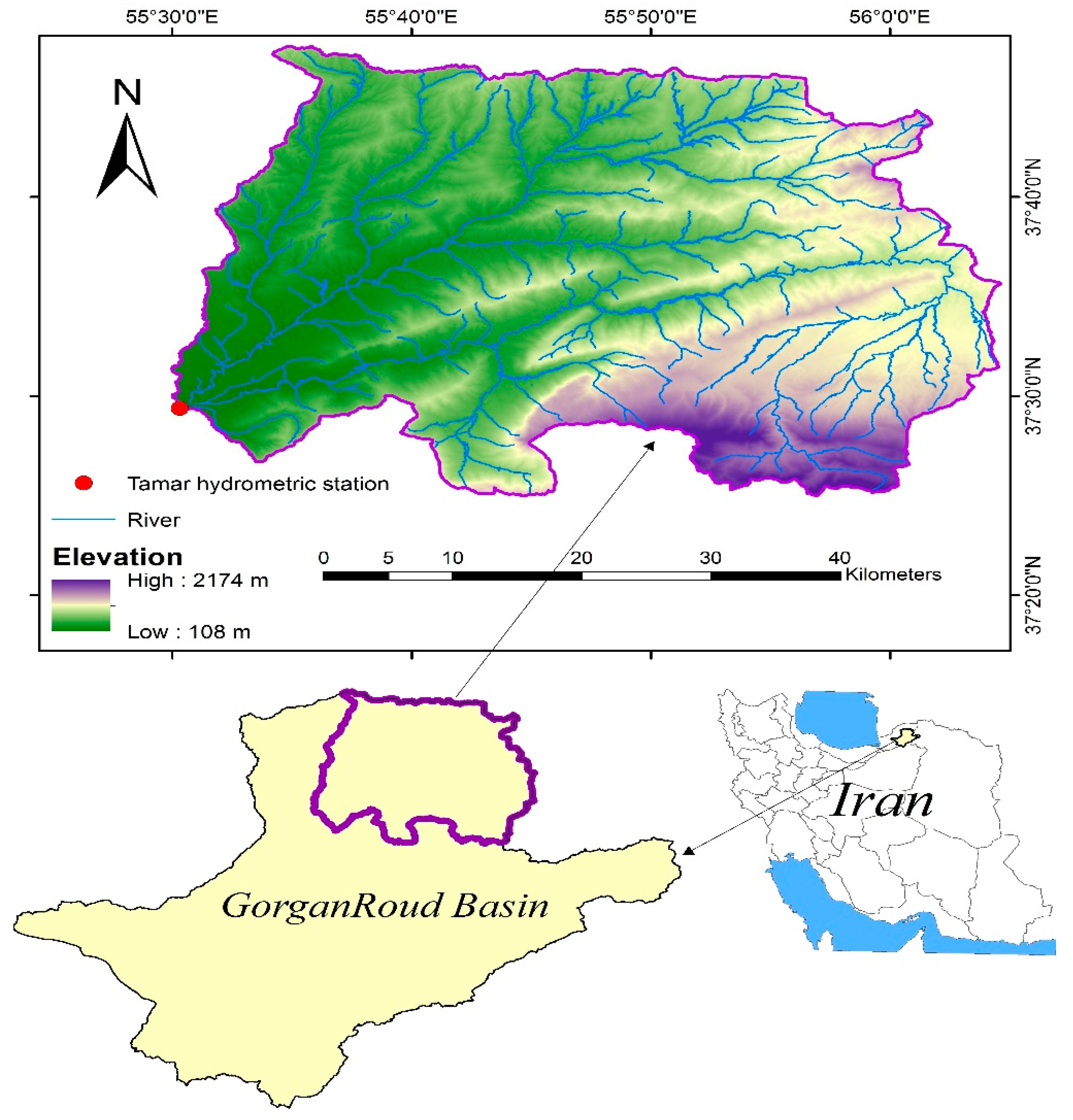
2.1. Study Area and Database
2.2. C-Factor
2.3. Input Scenarios
2.4. Data Preprocessing
2.5. Model Theory Background
2.5.1. Support Vector Regression (SVR)
2.5.2. Adaptive Neuro-Fuzzy Inference System (ANFIS)
2.5.3. Feed-Forward Neural Network (FFNN)
2.5.4. Radial Basis Function (RBF)
2.6. Model Evaluation
3. Results and Discussion
3.1. Results of the Best Lag Times for Inputs
3.2. Results of Optimal Structure for Different Models
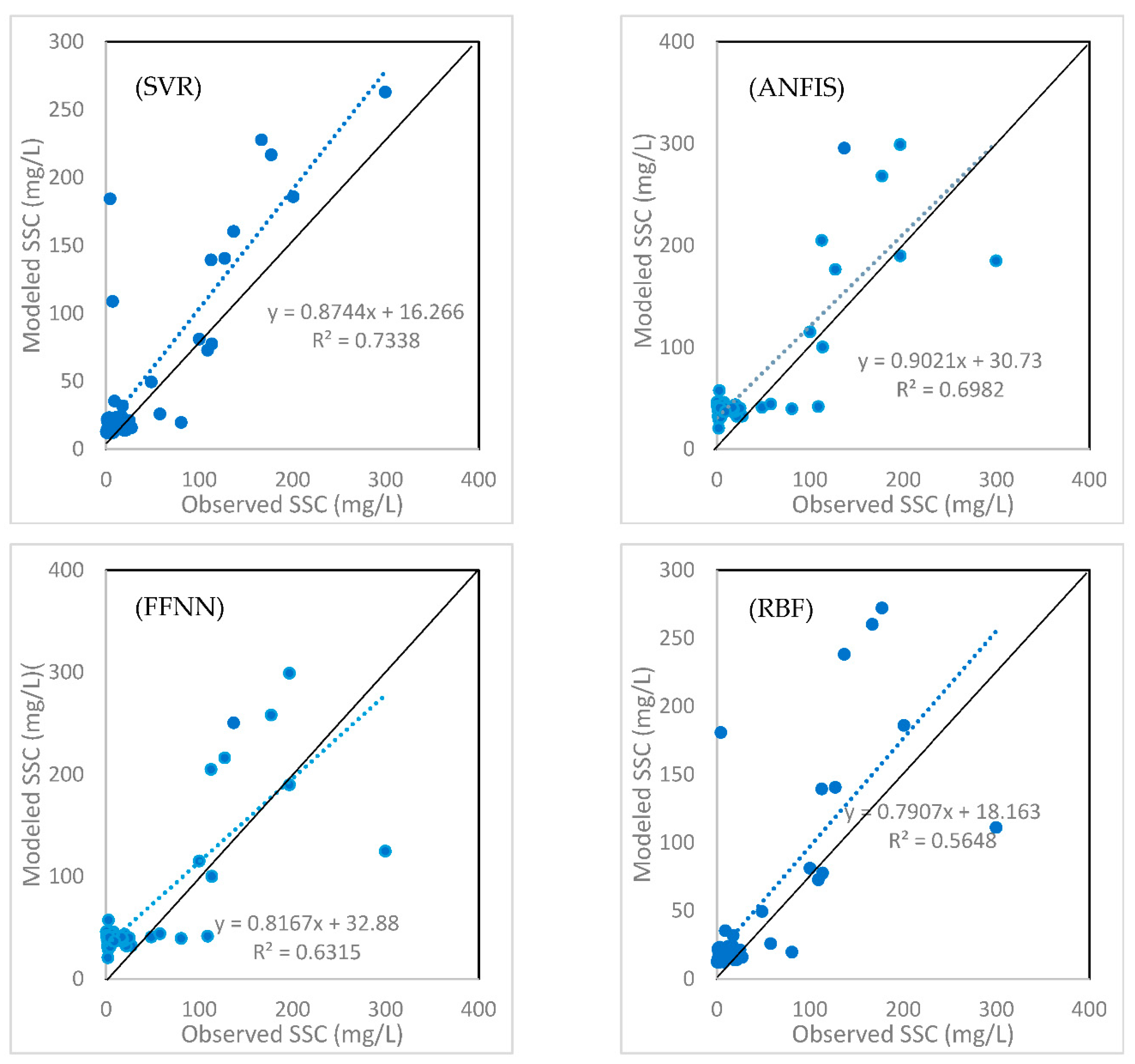
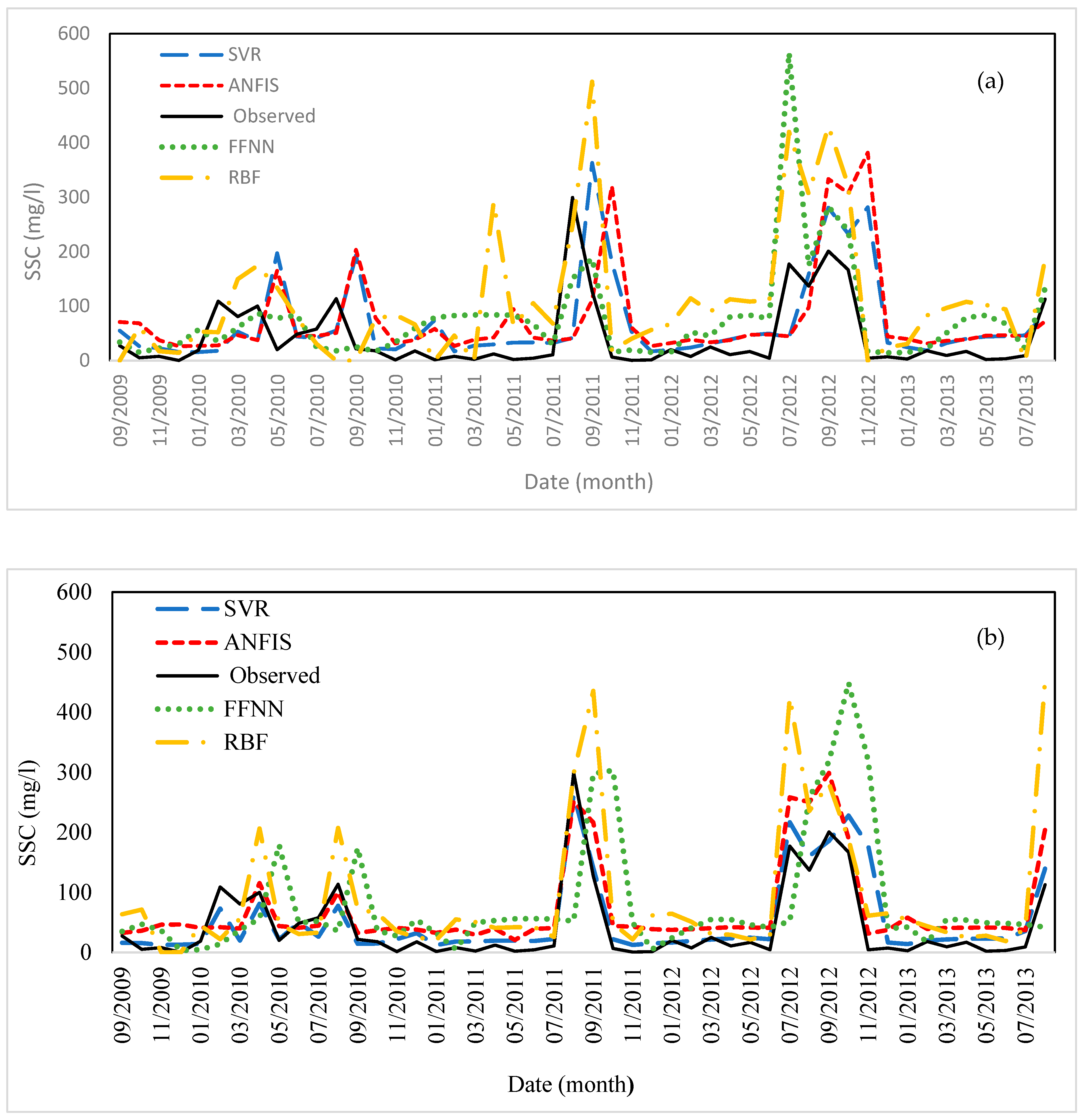
3.3. Evaluations and Results of Different Models and Input Scenarios for Estimating SSC
4. Conclusions
- The use of the C-factor in models elevated the performance of SSC modeling;
- Using only the discharge values of the same month did not accurately estimate SSC; other variables such as the monthly discharge with a 1-month time lag and the SSC within a 1-month time lag played important roles in this process;
- The SVR models performed best, followed by the ANFIS, FFNN, and RBF models, respectively. Based on the NS metric, the SVR and ANFIS models had good levels of performance, and the FFNN and RBF models had a lesser but satisfactory performance;
- The best input combination for models was determined as ;
- To construct an effective input scenario for estimating the monthly SSC, using the C-factor of the RUSLE as an input along with hydrological variables is important;
- Given that our optimization of the model parameters was accomplished through trial and error, we recommend surveying the meta-heuristic optimization algorithms, including the multi-objective and single-objective algorithms, for selecting those parameters that increase the accuracy of SSC estimation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ziegler, A.D.; Sidle, R.C.; Phang, V.X.; Wood, S.H.; Tantasirin, C. Bedload transport in SE Asian streams—Uncertainties and implications for reservoir management. Geomorphology 2014, 227, 31–48. [Google Scholar] [CrossRef]
- Zhu, Y.-M.; Lu, X.; Zhou, Y. Suspended sediment flux modeling with artificial neural network: An example of the Longchuanjiang River in the Upper Yangtze Catchment, China. Geomorphology 2007, 84, 111–125. [Google Scholar] [CrossRef]
- Sidle, R.C.; Milner, A.M. Stream development in Glacier Bay National Park, Alaska, USA. Arct. Alp. Res. 1989, 21, 350–363. [Google Scholar] [CrossRef]
- Pektaş, A.O.; Doğan, E. Prediction of bed load via suspended sediment load using soft computing methods. Geofizika 2015, 32, 27–46. [Google Scholar] [CrossRef]
- Buyukyildiz, M.; Kumcu, S.Y. An estimation of the suspended sediment load using adaptive network based fuzzy inference system, support vector machine and artificial neural network models. Water Resour. Manag. 2017, 31, 1343–1359. [Google Scholar] [CrossRef]
- Sarkar, A.; Sharma, N.; Singh, R. Sediment Runoff Modelling Using ANNs in an Eastern Himalayan Basin, India. In River System Analysis and Management; Springer: Berlin/Heidelberg, Germany, 2017; pp. 73–82. [Google Scholar]
- Khosravi, K.; Golkarian, A.; Melesse, A.M.; Deo, R.C. Suspended sediment load modeling using advanced hybrid Rotation Forest based Elastic Network approach. J. Hydrol. 2022, 610, 127963. [Google Scholar] [CrossRef]
- Rajaee, T.; Mirbagheri, S.A.; Zounemat-Kermani, M.; Nourani, V. Daily suspended sediment concentration simulation using ANN and neuro-fuzzy models. Sci. Total Environ. 2009, 407, 4916–4927. [Google Scholar] [CrossRef] [PubMed]
- Nhu, V.-H.; Khosravi, K.; Cooper, J.R.; Karimi, M.; Kisi, O.; Pham, B.T.; Lyu, Z. Monthly suspended sediment load prediction using artificial intelligence: Testing of a new random subspace method. Hydrol. Sci. J. 2020, 65, 2116–2127. [Google Scholar] [CrossRef]
- Khosravi, K.; Golkarian, A.; Booij, M.J.; Barzegar, R.; Sun, W.; Yaseen, Z.M.; Mosavi, A. Improving daily stochastic streamflow prediction: Comparison of novel hybrid data-mining algorithms. Hydrol. Sci. J. 2021, 66, 1457–1474. [Google Scholar] [CrossRef]
- Srinivasulu, S.; Jain, A. A comparative analysis of training methods for artificial neural network rainfall–runoff models. Appl. Soft Comput. 2006, 6, 295–306. [Google Scholar] [CrossRef]
- Dastorani, M.T.; Wright, N.G. A hydrodynamic/neural network approach for enhanced river flow prediction. Int. J. Civ. Eng. 2004, 2, 141–148. [Google Scholar]
- Wu, C.; Chau, K.W. Rainfall–runoff modeling using artificial neural network coupled with singular spectrum analysis. J. Hydrol. 2011, 399, 394–409. [Google Scholar] [CrossRef]
- Dastorani, M.T.; Moghadamnia, A.; Piri, J.; Rico-Ramirez, M. Application of ANN and ANFIS models for reconstructing missing flow data. Environ. Monit. Assess. 2010, 166, 421–434. [Google Scholar] [CrossRef] [PubMed]
- Dastorani, M.T.; Talebi, A.; Dastorani, M. Using neural networks to predict runoff from ungauged catchments. Asian J. Appl. Sci. 2010, 3, 399–410. [Google Scholar] [CrossRef]
- Dastorani, M.T.; Mahjoobi, J.; Talebi, A.; Fakhar, F. Application of Machine Learning Approaches in Rainfall-Runoff Modeling (Case Study: Zayandeh_Rood Basin in Iran). Civ. Eng. Infrastruct. J. 2018, 51, 293–310. [Google Scholar]
- Moatamednia, M.; Nohegar, A.; Malekian, A.; Asadi, H.; Tavasoli, A.; Safari, M.; Karimi, K. Daily river flow forecasting in a semi-arid region using twodatadriven. Desert 2015, 20, 11–21. [Google Scholar]
- Dastorani, M.T.; Koochi, J.S.; Darani, H.S.; Talebi, A.; Rahimian, M. River instantaneous peak flow estimation using daily flow data and machine-learning-based models. J. Hydroinf. 2013, 15, 1089–1098. [Google Scholar] [CrossRef]
- Moghaddam, H.K.; Moghaddam, H.K.; Kivi, Z.R.; Bahreinimotlagh, M.; Alizadeh, M.J. Developing comparative mathematic models, BN and ANN for forecasting of groundwater levels. Groundw. Sustain. Dev. 2019, 9, 100237. [Google Scholar] [CrossRef]
- Yoon, H.; Hyun, Y.; Ha, K.; Lee, K.-K.; Kim, G.-B. A method to improve the stability and accuracy of ANN-and SVM-based time series models for long-term groundwater level predictions. Comput. Geosci. 2016, 90, 144–155. [Google Scholar] [CrossRef]
- Dastorani, M.T.; Afkhami, H.; Sharifidarani, H.; Dastorani, M. Application of ANN and ANFIS models on dryland precipitation prediction (case study: Yazd in central Iran). J. Appl. Sci. 2010, 10, 2387–2394. [Google Scholar] [CrossRef]
- Dastorani, M.T.; Afkhami, H. Application of artificial neural networks on drought prediction in Yazd (Central Iran). Desert 2011, 16, 39–48. [Google Scholar]
- Melesse, A.; Ahmad, S.; McClain, M.; Wang, X.; Lim, Y. Suspended sediment load prediction of river systems: An artificial neural network approach. Agric. Water Manag. 2011, 98, 855–866. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Kişi, Ö.; Adamowski, J.; Ramezani-Charmahineh, A. Evaluation of data driven models for river suspended sediment concentration modeling. J. Hydrol. 2016, 535, 457–472. [Google Scholar] [CrossRef]
- Talebi, A.; Mahjoobi, J.; Dastorani, M.T.; Moosavi, V. Estimation of suspended sediment load using regression trees and model trees approaches (Case study: Hyderabad drainage basin in Iran). ISH J. Hydraul. Eng. 2017, 23, 212–219. [Google Scholar] [CrossRef]
- Asadi, H.; Dastorani, M.T.; Sidle, R.C.; Shahedi, K. Improving Flow Discharge-Suspended Sediment Relations: Intelligent Algorithms versus Data Separation. Water 2021, 13, 3650. [Google Scholar] [CrossRef]
- Roushangar, K.; Koosheh, A. Evaluation of GA-SVR method for modeling bed load transport in gravel-bed rivers. J. Hydrol. 2015, 527, 1142–1152. [Google Scholar] [CrossRef]
- Riahi-Madvar, H.; Seifi, A. Uncertainty analysis in bed load transport prediction of gravel bed rivers by ANN and ANFIS. Arab. J. Geosci. 2018, 11, 688. [Google Scholar] [CrossRef]
- Asheghi, R.; Hosseini, S.A. Prediction of bed load sediments using different artificial neural network models. Front. Struct. Civ. Eng. 2020, 14, 374–386. [Google Scholar] [CrossRef]
- Yang, C.T.; Marsooli, R.; Aalami, M.T. Evaluation of total load sediment transport formulas using ANN. Int. J. Sediment Res. 2009, 24, 274–286. [Google Scholar] [CrossRef]
- Noori, R.; Ghiasi, B.; Salehi, S.; Esmaeili Bidhendi, M.; Raeisi, A.; Partani, S.; Meysami, R.; Mahdian, M.; Hosseinzadeh, M.; Abolfathi, S. An Efficient Data Driven-Based Model for Prediction of the Total Sediment Load in Rivers. Hydrology 2022, 9, 36. [Google Scholar] [CrossRef]
- Choubin, B.; Darabi, H.; Rahmati, O.; Sajedi-Hosseini, F.; Kløve, B. River suspended sediment modelling using the CART model: A comparative study of machine learning techniques. Sci. Total Environ. 2018, 615, 272–281. [Google Scholar] [CrossRef]
- Gao, G.; Ning, Z.; Li, Z.; Fu, B. Prediction of long-term inter-seasonal variations of streamflow and sediment load by state-space model in the Loess Plateau of China. J. Hydrol. 2021, 600, 126534. [Google Scholar] [CrossRef]
- Banadkooki, F.B.; Ehteram, M.; Ahmed, A.N.; Teo, F.Y.; Ebrahimi, M.; Fai, C.M.; Huang, Y.F.; El-Shafie, A. Suspended sediment load prediction using artificial neural network and ant lion optimization algorithm. Environ. Sci. Pollut. Res. 2020, 27, 38094–38116. [Google Scholar] [CrossRef]
- Asadi, H.; Shahedi, K.; Sidle, R.C.; Kalami Heris, S.M. Prediction of Suspended Sediment Using Hydrologic and Hydrogeomorphic Data within Intelligence Models. Iran-Water Resour. Res. 2019, 15, 105–119. [Google Scholar]
- Kumar, D.; Pandey, A.; Sharma, N.; Flügel, W.-A. Daily suspended sediment simulation using machine learning approach. Catena 2016, 138, 77–90. [Google Scholar] [CrossRef]
- Khan, M.Y.A.; Tian, F.; Hasan, F.; Chakrapani, G.J. Artificial neural network simulation for prediction of suspended sediment concentration in the River Ramganga, Ganges Basin, India. Int. J. Sediment Res. 2019, 34, 95–107. [Google Scholar] [CrossRef]
- Chiang, J.-L.; Tsai, K.-J.; Chen, Y.-R.; Lee, M.-H.; Sun, J.-W. Suspended sediment load prediction using support vector machines in the Goodwin Creek experimental watershed. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 3–8 April 2011; p. 5285. [Google Scholar]
- Kisi, O.; Haktanir, T.; Ardiclioglu, M.; Ozturk, O.; Yalcin, E.; Uludag, S. Adaptive neuro-fuzzy computing technique for suspended sediment estimation. Adv. Eng. Softw. 2009, 40, 438–444. [Google Scholar] [CrossRef]
- Khosravi, K.; Mao, L.; Kisi, O.; Yaseen, Z.M.; Shahid, S. Quantifying hourly suspended sediment load using data mining models: Case study of a glacierized Andean catchment in Chile. J. Hydrol. 2018, 567, 165–179. [Google Scholar] [CrossRef]
- Rezaei, K.; Pradhan, B.; Vadiati, M.; Nadiri, A.A. Suspended sediment load prediction using artificial intelligence techniques: Comparison between four state-of-the-art artificial neural network techniques. Arab. J. Geosci. 2021, 14, 1–13. [Google Scholar] [CrossRef]
- Kumar, A.; Tripathi, V.K. Capability assessment of conventional and data-driven models for prediction of suspended sediment load. Environ. Sci. Pollut. Res. 2022, 29, 50040–50058. [Google Scholar] [CrossRef]
- Renard, K.G. Predicting Soil Erosion by Water: A Guide to Conservation Planning with the Revised Universal Soil Loss Equation (RUSLE); United States Government Printing: Washington, DC, USA, 1997. [Google Scholar]
- Kastridis, A.; Stathis, D.; Sapountzis, M.; Theodosiou, G. Insect outbreak and long-term post-fire effects on soil erosion in mediterranean suburban forest. Land 2022, 11, 911. [Google Scholar] [CrossRef]
- Ferreira, C.S.; Seifollahi-Aghmiuni, S.; Destouni, G.; Ghajarnia, N.; Kalantari, Z. Soil degradation in the European Mediterranean region: Processes, status and consequences. Sci. Total Environ. 2021, 805, 150106. [Google Scholar] [CrossRef] [PubMed]
- Durigon, V.; Carvalho, D.; Antunes, M.; Oliveira, P.; Fernandes, M. NDVI time series for monitoring RUSLE cover management factor in a tropical watershed. Int. J. Remote Sens. 2014, 35, 441–453. [Google Scholar] [CrossRef]
- Ghosal, K.; Das Bhattacharya, S. A review of RUSLE model. J. Indian Soc. Remote Sens. 2020, 48, 689–707. [Google Scholar] [CrossRef]
- Asadi, H.; Shahedi, K.; Jarihani, B.; Sidle, R.C. Rainfall-runoff modelling using hydrological connectivity index and artificial neural network approach. Water 2019, 11, 212. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Kumar, P.; Singh, V.K. Evaluating different machine learning models for runoff and suspended sediment simulation. Water Resour. Manag. 2019, 33, 1217–1231. [Google Scholar] [CrossRef]
- Vafakhah, M. Comparison of cokriging and adaptive neuro-fuzzy inference system models for suspended sediment load forecasting. Arab. J. Geosci. 2013, 6, 3003–3018. [Google Scholar] [CrossRef]
- Vapnik, V. The nature of statistical learning theory. IEEE Trans. Neural Netw. 1995, 195, 5. [Google Scholar]
- Kazemi, M.S.; Banihabib, M.E.; Soltani, J. A hybrid SVR-PSO model to predict concentration of sediment in typical and debris floods. Earth Sci. Inform. 2021, 14, 365–376. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Wang, H.; Xu, D. Parameter selection method for support vector regression based on adaptive fusion of the mixed kernel function. J. Control Sci. Eng. 2017, 2017. [Google Scholar] [CrossRef]
- Chen, S.-T.; Yu, P.-S. Pruning of support vector networks on flood forecasting. J. Hydrol. 2007, 347, 67–78. [Google Scholar] [CrossRef]
- Jang, J.-S. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Chen, S.H.; Lin, Y.H.; Chang, L.C.; Chang, F.J. The strategy of building a flood forecast model by neuro-fuzzy network. Hydrol. Processes: Int. J. 2006, 20, 1525–1540. [Google Scholar] [CrossRef]
- Jang, J.-S.R.; Sun, C.-T. Neuro-fuzzy modeling and control. Proc. IEEE 1995, 83, 378–406. [Google Scholar] [CrossRef]
- Pumo, D.; Francipane, A.; Lo Conti, F.; Arnone, E.; Bitonto, P.; Viola, F.; La Loggia, G.; Noto, L. The SESAMO early warning system for rainfall-triggered landslides. J. Hydroinformatics 2016, 18, 256–276. [Google Scholar] [CrossRef]
- Nourani, V.; Kisi, Ö.; Komasi, M. Two hybrid artificial intelligence approaches for modeling rainfall–runoff process. J. Hydrol. 2011, 402, 41–59. [Google Scholar] [CrossRef]
- Goyal, M.K.; Bharti, B.; Quilty, J.; Adamowski, J.; Pandey, A. Modeling of daily pan evaporation in sub tropical climates using ANN, LS-SVR, Fuzzy Logic, and ANFIS. Expert Syst. Appl. 2014, 41, 5267–5276. [Google Scholar] [CrossRef]
- Kim, T.-W.; Valdés, J.B. Nonlinear model for drought forecasting based on a conjunction of wavelet transforms and neural networks. J. Hydrol. Eng. 2003, 8, 319–328. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Broomhead, D.S.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; Royal Signals and Radar Establishment Malvern: UK, 1988. [Google Scholar]
- Alp, M.; Cigizoglu, H.K. Suspended sediment load simulation by two artificial neural network methods using hydrometeorological data. Environ. Model. Softw. 2007, 22, 2–13. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Bonakdari, H.; Zaji, A.H. An expert system with radial basis function neural network based on decision trees for predicting sediment transport in sewers. Water Sci. Technol. 2016, 74, 176–183. [Google Scholar] [CrossRef] [PubMed]
- Isa, M.M.M. Comparative study of MLP and RBF neural networks for estimation of suspended sediments in Pari River, Perak. Res. J. Appl. Sci. Eng. Technol. 2014, 7, 3837–3841. [Google Scholar]
- Haykin, S. Neural Networks, a comprehensive foundation, Prentice-Hall Inc. Up. Saddle River New Jersey 1999, 7458, 161–175. [Google Scholar]
- Sudheer, K.; Jain, S. Radial basis function neural network for modeling rating curves. J. Hydrol. Eng. 2003, 8, 161–164. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Jang, J.-S.R.; Sun, C.-T.; Mizutani, E. Neuro-fuzzy and soft computing-a computational approach to learning and machine intelligence [Book Review]. IEEE Trans. Autom. Control 1997, 42, 1482–1484. [Google Scholar] [CrossRef]
- Kastridis, A.; Theodosiou, G.; Fotiadis, G. Investigation of Flood Management and Mitigation Measures in Ungauged NATURA Protected Watersheds. Hydrology 2021, 8, 170. [Google Scholar] [CrossRef]
- Singh, J.; Knapp, H.V.; Arnold, J.G.; Demissie, M. Hydrological modeling of the Iroquois river watershed using HSPF and SWAT. JAWRA J. Am. Water Resour. Assoc. 2005, 41, 343–360. [Google Scholar] [CrossRef]
- Sichingabula, H.M. Factors controlling variations in suspended sediment concentration for single-valued sediment rating curves, Fraser River, British Columbia, Canada. Hydrol. Processes 1998, 12, 1869–1894. [Google Scholar] [CrossRef]
- Lafdani, E.K.; Nia, A.M.; Ahmadi, A. Daily suspended sediment load prediction using artificial neural networks and support vector machines. J. Hydrol. 2013, 478, 50–62. [Google Scholar] [CrossRef]
- Kisi, O.; Dailr, A.H.; Cimen, M.; Shiri, J. Suspended sediment modeling using genetic programming and soft computing techniques. J. Hydrol. 2012, 450, 48–58. [Google Scholar] [CrossRef]
- Samet, K.; Hoseini, K.; Karami, H.; Mohammadi, M. Comparison between soft computing methods for prediction of sediment load in rivers: Maku dam case study. Iran. J. Sci. Technol. Trans. Civ. Eng. 2019, 43, 93–103. [Google Scholar] [CrossRef]
- Pantazi, X.; Moshou, D.; Bochtis, D. Chapter 2—Artificial intelligence in agriculture. In Intelligent Data Mining and Fusion Systems in Agriculture; Pantazi, X.E., Moshou, D., Bochtis, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 17–101. [Google Scholar]
- Rodríguez-Blanco, M.; Taboada-Castro, M.; Palleiro, L.; Taboada-Castro, M. Temporal changes in suspended sediment transport in an Atlantic catchment, NW Spain. Geomorphology 2010, 123, 181–188. [Google Scholar] [CrossRef]
- Salih, S.Q.; Sharafati, A.; Khosravi, K.; Faris, H.; Kisi, O.; Tao, H.; Ali, M.; Yaseen, Z.M. River suspended sediment load prediction based on river discharge information: Application of newly developed data mining models. Hydrol. Sci. J. 2020, 65, 624–637. [Google Scholar] [CrossRef]
- Hosseini, S.M.; Mahjouri, N. Integrating support vector regression and a geomorphologic artificial neural network for daily rainfall-runoff modeling. Appl. Soft Comput. 2016, 38, 329–345. [Google Scholar] [CrossRef]
- Ziegler, A.D.; Benner, S.G.; Tantasirin, C.; Wood, S.H.; Sutherland, R.A.; Sidle, R.C.; Jachowski, N.; Nullet, M.A.; Xi, L.X.; Snidvongs, A. Turbidity-based sediment monitoring in northern Thailand: Hysteresis, variability, and uncertainty. J. Hydrol. 2014, 519, 2020–2039. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Statistical Parameter | Boostan Dam Watershed | ||
|---|---|---|---|---|
| Training (70%) | Test (30%) | Total Data | ||
| 114 | 48 | 162 | ||
| SSC (mg/L) | Period (m/y) | 4/2000–9/2009 | 10/2009–9/2013 | 4/2000–9/2013 |
| 0.01 | 0.24 | 0.01 | ||
| 9259.15 | 299.63 | 9259.15 | ||
| 199.99 | 45.14 | 154.11 | ||
| 940.87 | 68.59 | 792.28 | ||
| 8.46 | 1.97 | 10.07 | ||
| 78.50 | 3.50 | 111.40 | ||
| Q (m3/s) | 0.00 | 0.01 | 0.00 | |
| 10.40 | 3.13 | 10.40 | ||
| 1.04 | 0.84 | 0.98 | ||
| 1.11 | 0.75 | 1.02 | ||
| 2.96 | 1.53 | 2.93 | ||
| 14.30 | 1.61 | 14.80 | ||
| C | 0.19 | 0.21 | 0.19 | |
| 0.43 | 0.41 | 0.43 | ||
| 0.33 | 0.34 | 0.33 | ||
| 0.05 | 0.04 | 0.05 | ||
| −0.86 | −1.30 | −0.98 | ||
| 0.25 | 1.38 | 0.50 | ||
| Scenario Number | Group Name | Inputs | Output |
|---|---|---|---|
| 1 | Group 1 | ||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | Group 2 | ||
| 7 | |||
| 8 | |||
| 9 | |||
| 10 |
| Lag | Cross-Correlation | Partial Autocorrelation |
|---|---|---|
| 0 | 0.87 | - |
| 1 | 0.19 | 0.21 |
| 2 | 0.09 | 0.01 |
| 3 | 0.01 | −0.03 |
| 4 | −0.08 | −0.14 |
| 5 | −0.10 | −0.15 |
| 6 | −0.01 | −0.03 |
| Scenario Number | FFNN | RBF | ANFIS | SVR | ||||
|---|---|---|---|---|---|---|---|---|
| No. HN | No. HN | No. MF | MF | C | ε | |||
| 1 | 5 | 0.3 | 20 | 3 | Gaussian-2 | 0.17 | 5 | 0.001 |
| 2 | 7 | 0.2 | 15 | 5 | Gaussian | 0.13 | 5 | 0.001 |
| 3 | 4 | 0.5 | 16 | 3 | Gaussian-2 | 0.17 | 1 | 0.1 |
| 4 | 8 | 0.4 | 18 | 4 | Bell | 0.15 | 10 | 0.001 |
| 5 | 8 | 0.3 | 21 | 4 | Gaussian-2 | 0.16 | 10 | 0.001 |
| 6 | 6 | 0.1 | 16 | 6 | Gaussian | 0.15 | 2.5 | 0.1 |
| 7 | 8 | 0.4 | 19 | 5 | Gaussian-2 | 0.19 | 2 | 0.01 |
| 8 | 7 | 0.3 | 18 | 5 | Bell | 0.17 | 5 | 0.01 |
| 9 | 10 | 0.2 | 20 | 4 | Gaussian-2 | 0.17 | 10 | 0.0001 |
| 10 | 10 | 0.7 | 16 | 4 | Gaussian | 0.21 | 10 | 0.0001 |
| Input Patterns | Training | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE (mg/L) | NS | MAE (mg/L) | R2 | RMSE (mg/L) | NS | MAE (mg/L) | R2 | |
| 214.01 | 0.66 | 92.58 | 0.70 | 203.19 | 0.56 | 99.11 | 0.66 | |
| 221.52 | 0.64 | 93.09 | 0.73 | 223.24 | 0.54 | 106.63 | 0.63 | |
| 439.23 | 0.35 | 201.63 | 0.38 | 444.11 | 0.29 | 222.71 | 0.33 | |
| 199.32 | 0.68 | 88.71 | 0.76 | 211.96 | 0.55 | 99.76 | 0.63 | |
| 195.51 | 0.72 | 79.50 | 0.79 | 201.85 | 0.61 | 96.92 | 0.66 | |
| 181.81 | 0.71 | 77.41 | 0.80 | 199.64 | 0.65 | 91.76 | 0.69 | |
| 178.65 | 0.74 | 72.31 | 0.83 | 191.54 | 0.69 | 84.39 | 0.71 | |
| 297.96 | 0.39 | 166.35 | 0.49 | 317.68 | 0.35 | 177.19 | 0.44 | |
| 168.95 | 0.83 | 64.45 | 0.90 | 183.12 | 0.71 | 78.39 | 0.76 | |
| 159.71 | 0.89 | 61.56 | 0.92 | 171.82 | 0.73 | 73.67 | 0.78 | |
| Input Patterns | Training | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE (mg/L) | NS | MAE (mg/L) | R2 | RMSE (mg/L) | NS | MAE (mg/L) | R2 | |
| 237.37 | 0.60 | 99.11 | 0.65 | 239.66 | 0.53 | 121.07 | 0.54 | |
| 232.07 | 0.61 | 100.15 | 0.70 | 241.33 | 0.49 | 118.17 | 0.59 | |
| 509.11 | 0.28 | 209.29 | 0. 35 | 592.23 | 0.21 | 276.91 | 0.30 | |
| 222.59 | 0.63 | 96.47 | 0.74 | 231.88 | 0.50 | 108.09 | 0.61 | |
| 201.15 | 0.67 | 92.53 | 0.78 | 227.95 | 0.55 | 101.05 | 0.65 | |
| 196.87 | 0.69 | 81.68 | 0.79 | 225.05 | 0.57 | 99.08 | 0.65 | |
| 193.94 | 0.71 | 79.20 | 0.81 | 221.88 | 0.61 | 94.91 | 0.68 | |
| 310.39 | 0.37 | 178.74 | 0.44 | 369.28 | 0.34 | 198.32 | 0.40 | |
| 177.90 | 0.81 | 67.95 | 0.89 | 198.95 | 0.70 | 79.24 | 0.73 | |
| 183.87 | 0.75 | 73.06 | 0.87 | 216.41 | 0.67 | 91.20 | 0.71 | |
| Input Patterns | Training | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE (mg/L) | NS | MAE (mg/L) | R2 | RMSE (mg/L) | NS | MAE (mg/L) | R2 | |
| 257.37 | 0.41 | 129.17 | 0.47 | 269.66 | 0.38 | 131.57 | 0.44 | |
| 241.11 | 0.50 | 120.13 | 0.59 | 253.33 | 0.43 | 128.06 | 0.51 | |
| 571.11 | 0.19 | 224.02 | 0. 25 | 634.23 | 0.11 | 299.98 | 0.17 | |
| 212.39 | 0.55 | 106.47 | 0.67 | 242.88 | 0.48 | 117.19 | 0.56 | |
| 207.15 | 0.59 | 98.53 | 0.71 | 229.95 | 0.52 | 99.29 | 0.61 | |
| 208.87 | 0.57 | 101.68 | 0.68 | 239.05 | 0.47 | 109.16 | 0.51 | |
| 201.94 | 0.61 | 99.20 | 0.71 | 231.88 | 0.51 | 98.91 | 0.58 | |
| 333.19 | 0.30 | 191.41 | 0.39 | 401.28 | 0.24 | 208.21 | 0.34 | |
| 186.90 | 0.74 | 74.95 | 0.79 | 201.95 | 0.63 | 85.24 | 0.69 | |
| 196.62 | 0.67 | 81.22 | 0.77 | 226.51 | 0.59 | 97.30 | 0.66 | |
| Input Patterns | Training | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE (mg/L) | NS | MAE (mg/L) | R2 | RMSE (mg/L) | NS | MAE (mg/L) | R2 | |
| 267.37 | 0.31 | 139.17 | 0.43 | 269.66 | 0.28 | 146.57 | 0.34 | |
| 254.11 | 0.41 | 130.13 | 0.46 | 273.33 | 0.32 | 139.06 | 0.41 | |
| 593.11 | 0.11 | 244.02 | 0. 19 | 664.23 | 0.09 | 301.98 | 0.13 | |
| 231.39 | 0.49 | 126.47 | 0.51 | 252.88 | 0.39 | 137.19 | 0.45 | |
| 216.15 | 0.53 | 116.53 | 0.61 | 240.95 | 0.43 | 121.29 | 0.51 | |
| 228.87 | 0.50 | 124.68 | 0.59 | 243.05 | 0.42 | 131.16 | 0.48 | |
| 211.94 | 0.55 | 119.20 | 0.64 | 239.88 | 0.46 | 128.91 | 0.54 | |
| 351.19 | 0.25 | 198.41 | 0.31 | 452.28 | 0.19 | 226.21 | 0.27 | |
| 204.90 | 0.61 | 98.95 | 0.69 | 235.95 | 0.52 | 108.24 | 0.59 | |
| 198.12 | 0.65 | 89.13 | 0.75 | 231.01 | 0.56 | 99.89 | 0.65 | |
| Model | The Best Input Pattern in Group 1 | %REp | The Best Input Pattern in Group 1 | %REp |
|---|---|---|---|---|
| SVR | 21.13 | −12.21 | ||
| ANFIS | 27.39 | −12.28 | ||
| FFNN | 70.56 | 49.94 | ||
| RBF | 88.89 | 51.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asadi, H.; Dastorani, M.T.; Khosravi, K.; Sidle, R.C. Applying the C-Factor of the RUSLE Model to Improve the Prediction of Suspended Sediment Concentration Using Smart Data-Driven Models. Water 2022, 14, 3011. https://doi.org/10.3390/w14193011
Asadi H, Dastorani MT, Khosravi K, Sidle RC. Applying the C-Factor of the RUSLE Model to Improve the Prediction of Suspended Sediment Concentration Using Smart Data-Driven Models. Water. 2022; 14(19):3011. https://doi.org/10.3390/w14193011
Chicago/Turabian StyleAsadi, Haniyeh, Mohammad T. Dastorani, Khabat Khosravi, and Roy C. Sidle. 2022. "Applying the C-Factor of the RUSLE Model to Improve the Prediction of Suspended Sediment Concentration Using Smart Data-Driven Models" Water 14, no. 19: 3011. https://doi.org/10.3390/w14193011