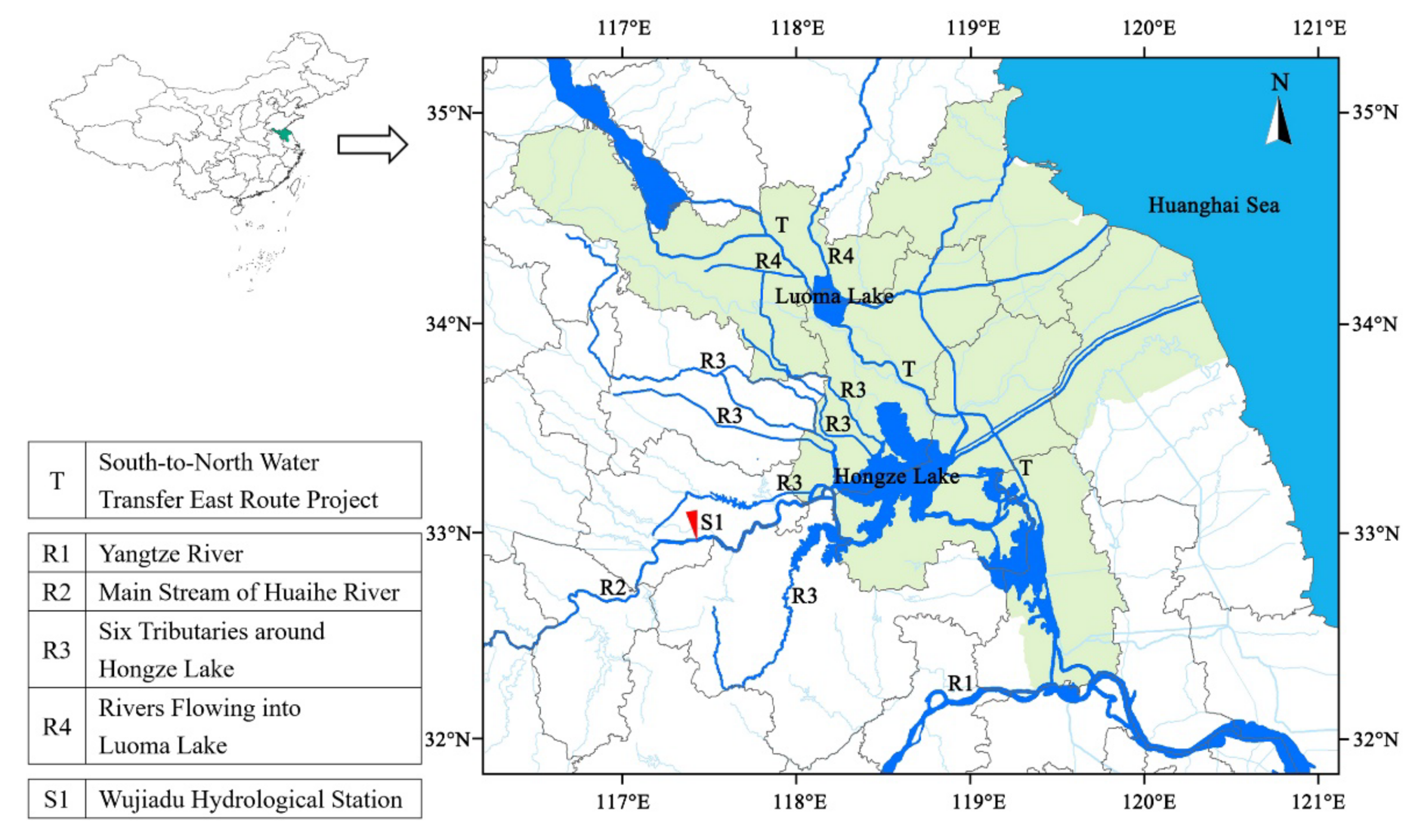
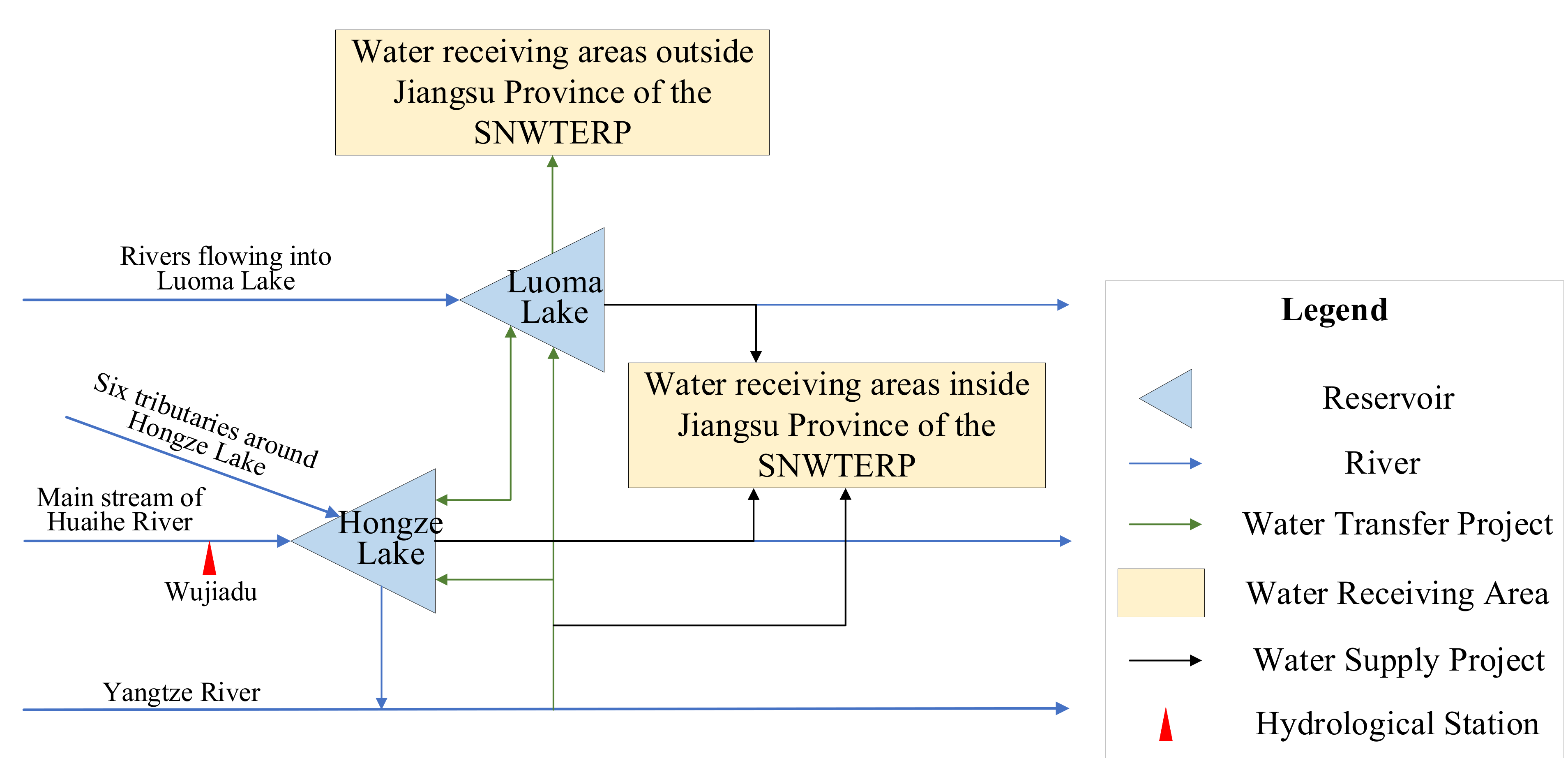
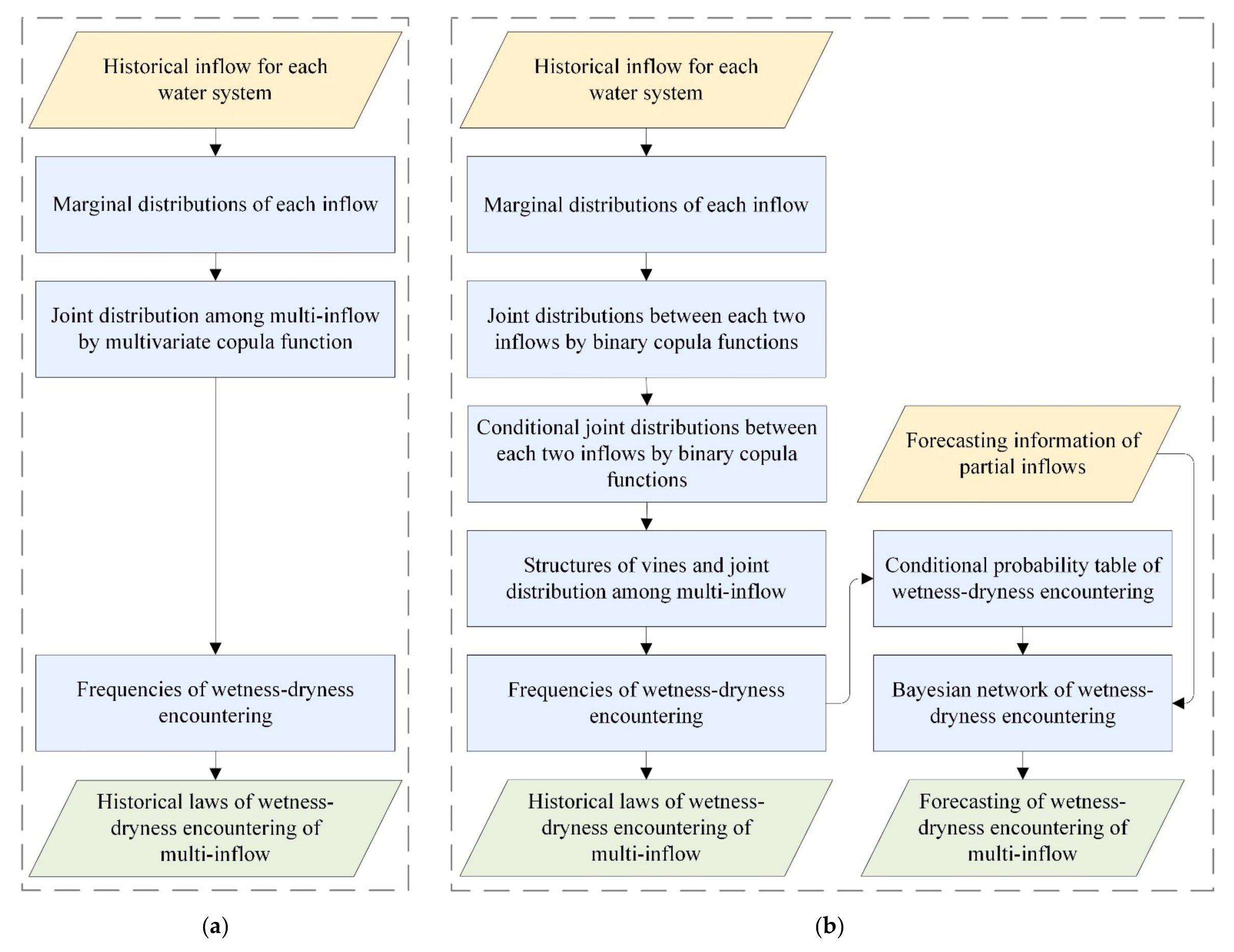
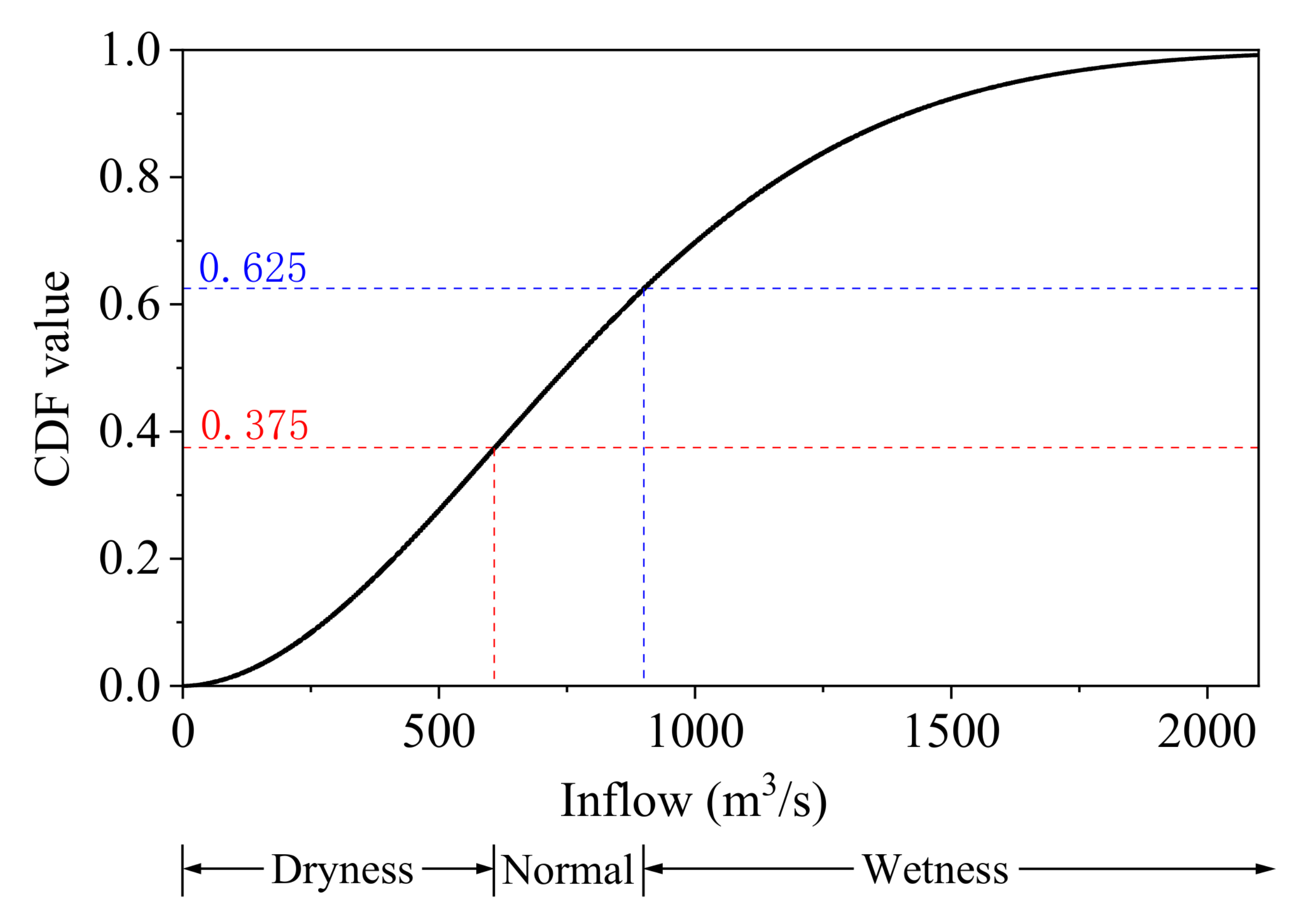
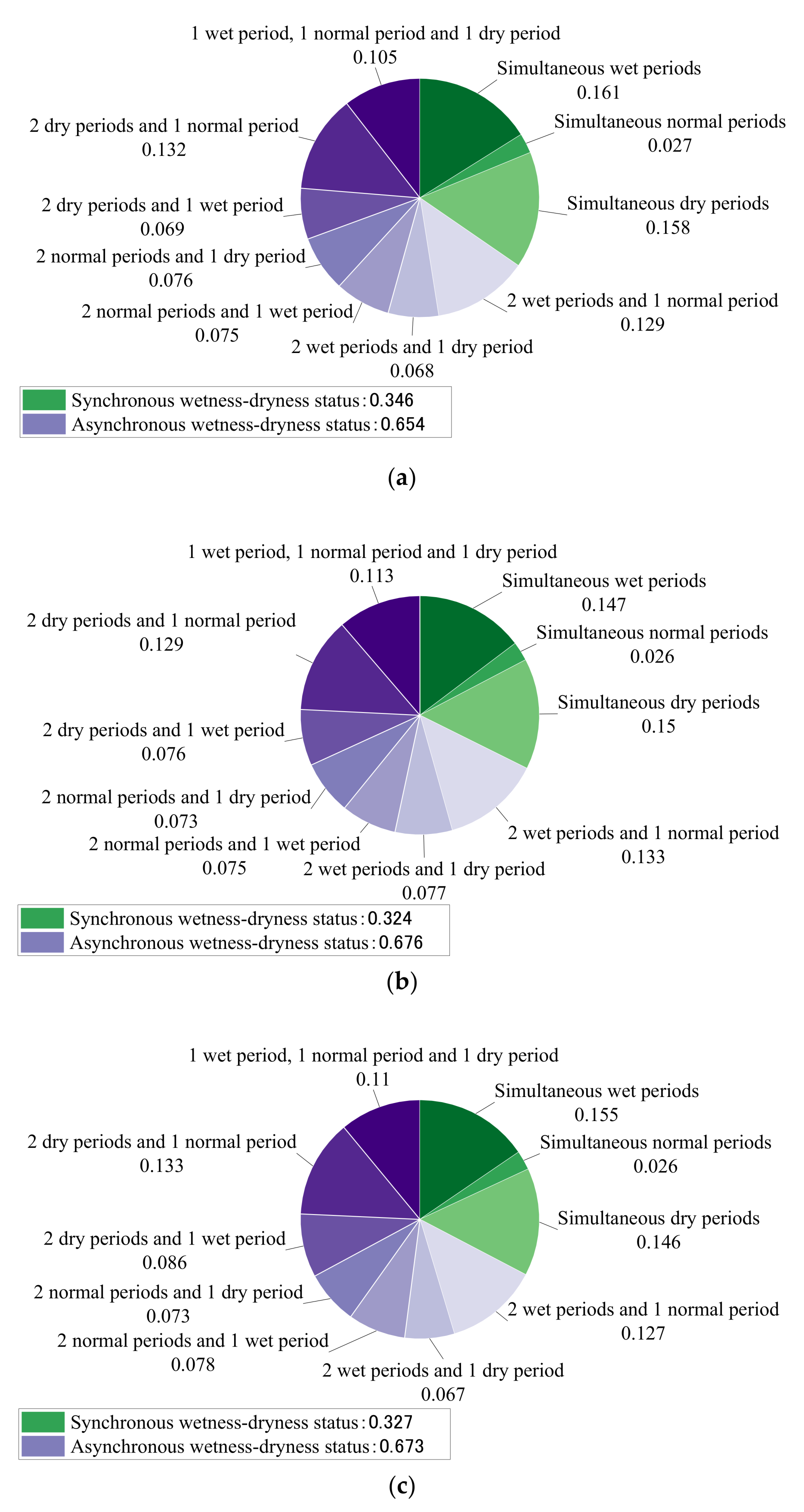
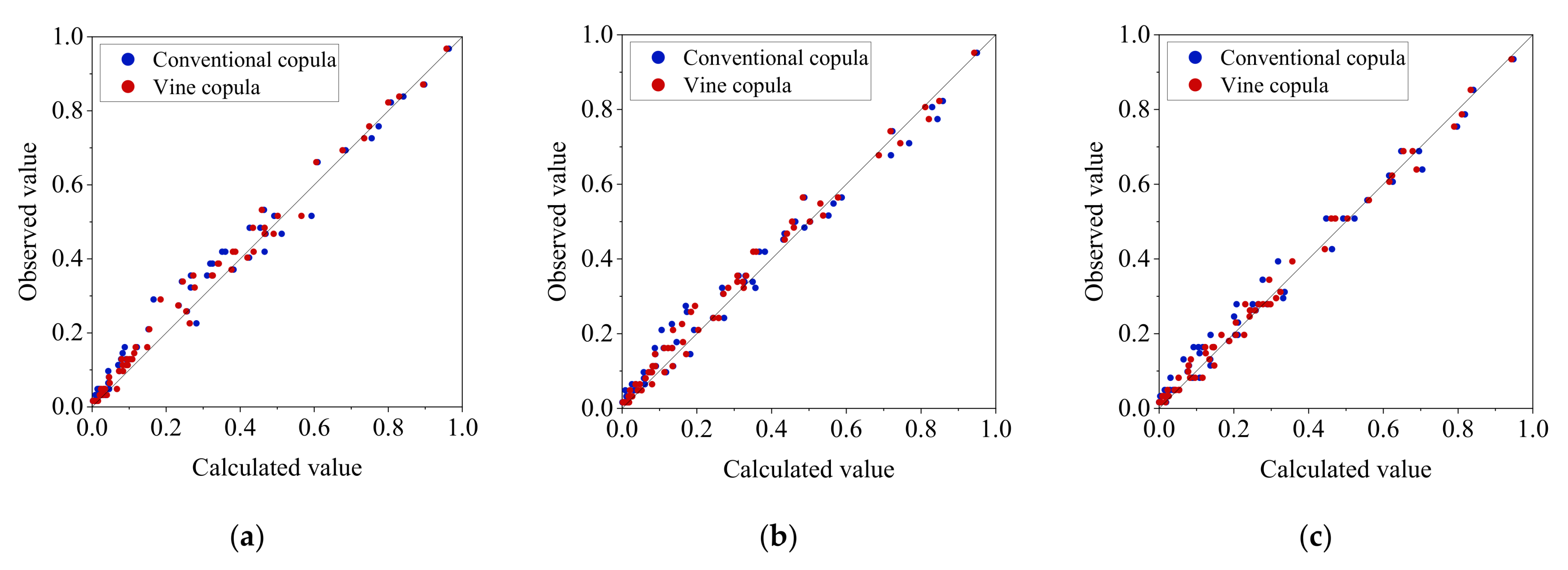
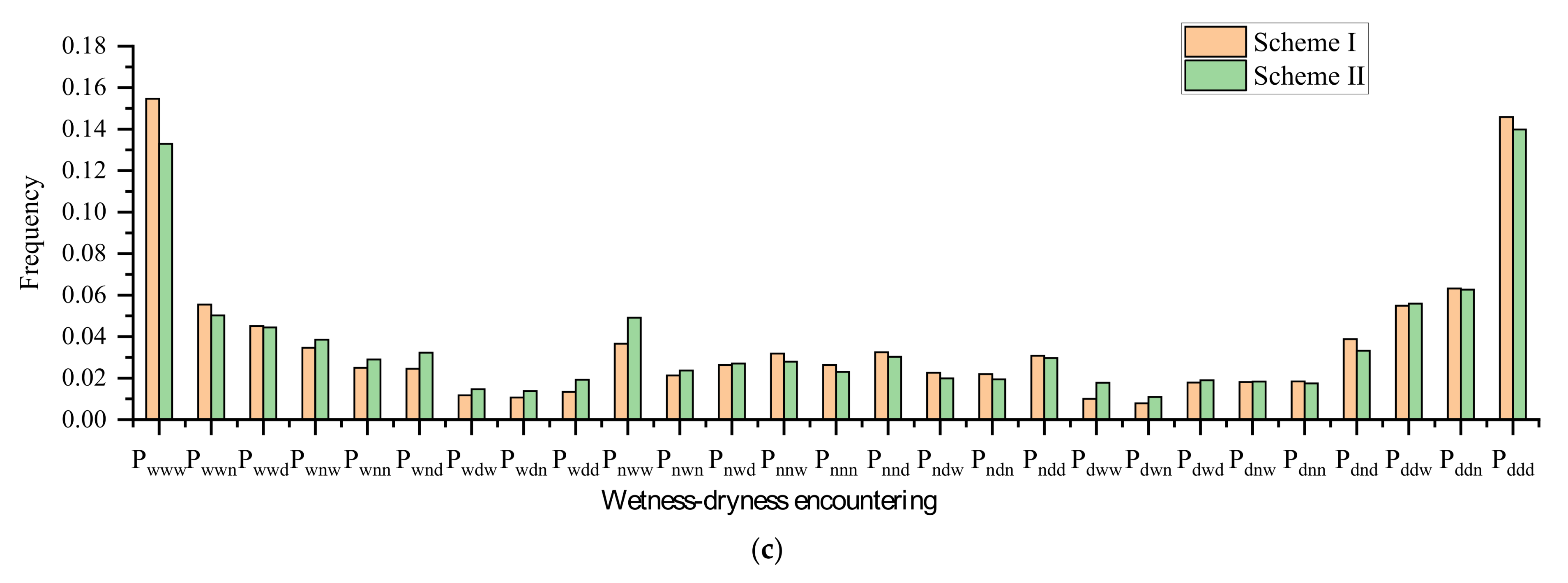
The wetness-dryness encountering of a multi-water system can be analyzed and forecast by the vine copula function-Bayesian network model proposed in this paper. In this model, the joint distribution of multiple water systems is constructed using the vine copula function, and then the historical statistical probability of wetness-dryness encountering of the multi-water source can be calculated by the joint distribution. The Bayesian network is constructed using the conditional probability table calculated by the historical probability of wetness-dryness encountering. Wetness-dryness encountering in the coming period can be forecast by the Bayesian network.
3.2.1. Construction of Joint Distribution among Multi-Inflow
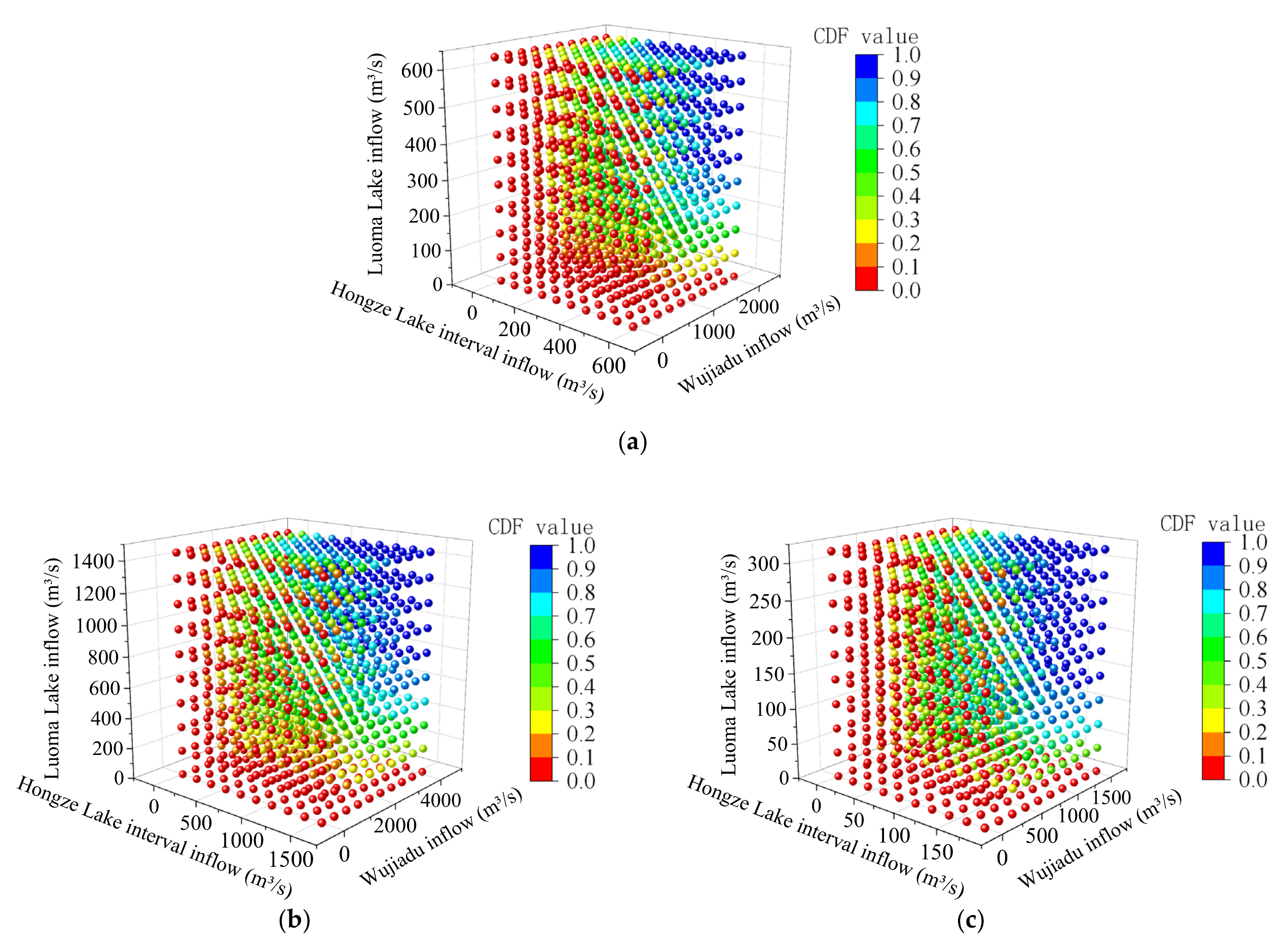
The joint distribution of multi-inflow is constructed by the vine copula function. The vine copula function is developed from the conventional copula function, which can be traced back to Sklar’s theorem [
37] proposed by Sklar in 1959, the main content of which is: for a multivariate random variable
, there exist marginal distributions
and joint distribution
, then there exists a copula function
C such that
if
are continuous functions, then
C is unique.
The vine copula function consists of a stack of conventional binary copula functions, which copulas marginal distributions or conditional marginal distributions [
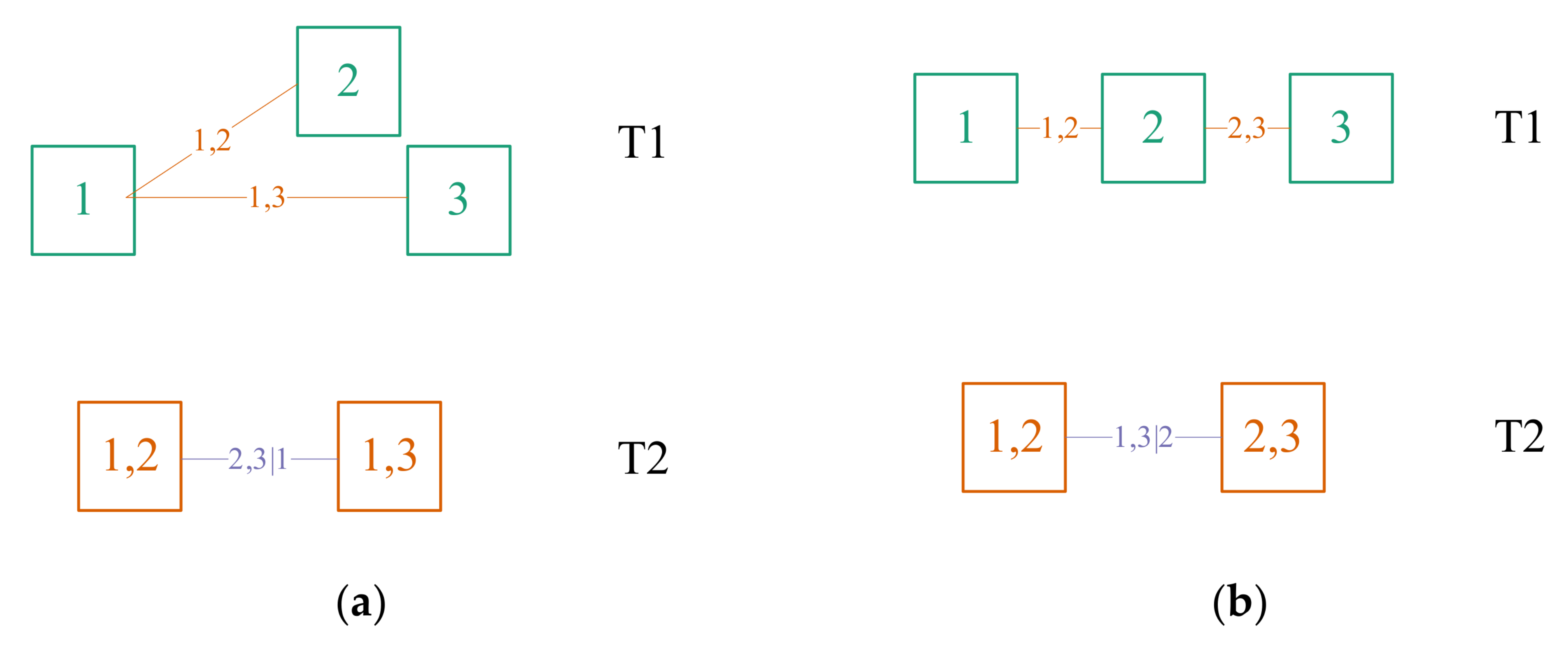
25], and their dependence structure can be graphically represented as vines. For example, two kinds of three-dimensional vine copula structures are shown in
Figure 5. In vine copula structure, the vine consists of a series of trees, such as ‘T1’ and ‘T2’ in
Figure 5a or
Figure 5b; each tree consists of nodes (such as ‘1’ and ‘2’ in ‘T1’ in
Figure 5a or
Figure 5b, etc.) and edges (such as ‘1,2’ in ‘T1’ in
Figure 5a or
Figure 5b, etc.). Except the last tree, the edges of each tree are used as the nodes of the next tree. The nodes in the first tree represent the marginal distributions of each variable, such as ‘1’ represents
; the edges in the first tree represent the binary joint distributions of the two nodes linked, such as ‘1,2’ represents
; the edges in other trees represent the binary conditional joint distributions of the two nodes linked, such as ‘1,3|2’ represents
.
The three-dimensional vine copula function has two kinds of structures: the canonical vine copula and the D-vine copula. In canonical vine copula structure, there is one central node in each tree that is linked to all edges, as shown in
Figure 5a; in D-vine copula structure, each node is linked to at most two edges, as shown in
Figure 5b. When using the canonical vine copula structure, not only the central node of the first tree but also the central node of each subsequent tree needs to be determined; when using the D-vine copula structure, since all the trees are in the form of chains, once the order of the nodes of the first tree is determined, the subsequent trees are also determined.
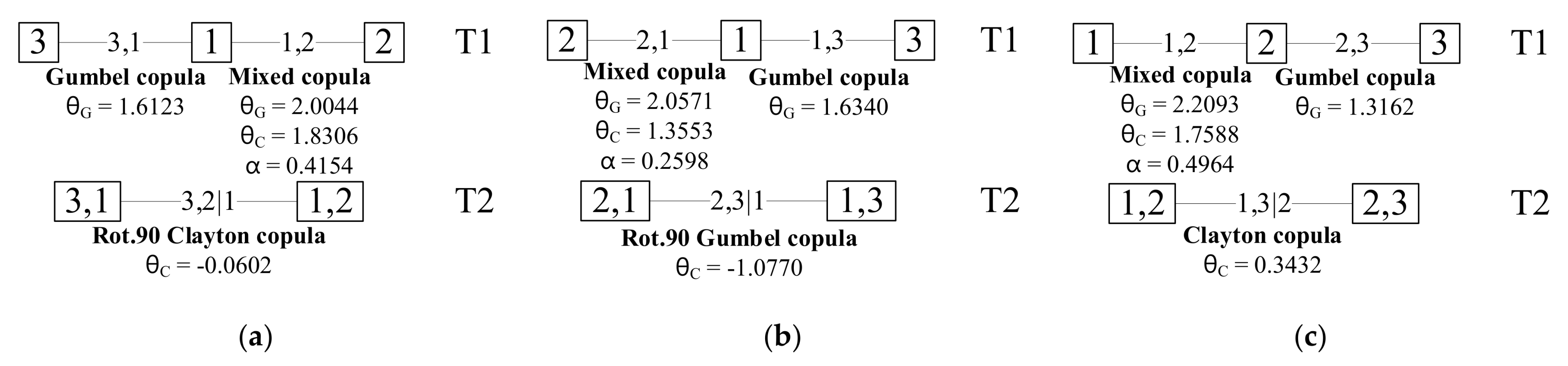
When choosing copula functions, different copula functions have different characteristics and applicability conditions. Gumbel copula is suitable for portraying random variables with upper-tail correlation, such as design flood; Clayton copula is suitable for portraying random variables with lower-tail correlation, such as dry-season runoff. Considering that it is often difficult for a single copula function to accurately capture the correlation structure among variables, a mixed copula function of Gumbel copula and Clayton copula is constructed in this paper, as follows:
where
is the ratio of
in the mixed copula;
is Gumbel copula,
is the parameter of Gumbel copula;
is Clayton copula,
is the parameter of Clayton copula;
is the mixed copula.
The binary Gumbel copula and Clayton copula can only be applied in the case of a positive correlation between two variables. In this paper, when the case of negative correlation is encountered, the copula function is rotated by 90 degrees and the transformation relationship is as follows:
where
is the copula function after 90° rotation (Rot.90 copula);
is the parameter of copula after 90° rotation. Like the original copula function, the rotated copula function can construct the mixed copula function and be used as the basis for the construction of the vine copula function.
The flowchart of construction of the joint distribution by vine copula function can be found in
Figure 3b, and the specific steps are as follows:
Fitting of the marginal distribution of each inflow means the determination of the nodes in the first tree in the vine copula function. The maximum likelihood method is used for parameter estimation among the commonly used distribution models in hydrology [
38,
39], and then the fitting test is performed using Kolmogorov–Smirnov(K-S) test. Among the tested distribution models, the appropriate distribution model is selected according to goodness-of-fit evaluation indexes such as RMSE value and AIC value, and the marginal distribution of each inflow is determined.
- 2.
Construction of the joint distributions between each two inflows.
Here to determine edges in the first tree. The inflow series is introduced into the respective marginal distribution to obtain the marginal CDF value series. Kendall’s tau coefficient ( value) of each two inflows is calculated from the marginal CDF value series. If , the two variables are positively correlated, the parameter estimation is performed for the binary Gumbel copula and Clayton copula; if , the two variables are negatively correlated, the parameter estimation is performed for the binary Gumbel copula rotated 90° and Clayton copula rotated 90°. The maximum likelihood method is employed for parameter estimation, and the nonlinear programming method was used to obtain the α value of the mixed copula, taking the RMSE value minimum as the objective function. Then the fitting test is performed, and among the copula functions that pass the test, the appropriate copula function is selected based on the results of the goodness-of-fit evaluation.
- 3.
Construction of the conditional joint distributions between each two inflows.
Here, we determine the edges of trees except the first tree. From the edges of the previous one tree, the conditional marginal distributions of each inflow are derived. The inflow series or the marginal CDF value series obtained in the previous step is introduced into the respective conditional marginal distribution, in order to obtain the conditional marginal CDF value series. The conditional joint distributions between each two inflows are constructed from the conditional marginal CDF value series by the binary copula function, and the method is the same as that in step 2. The derivation of the conditional marginal distributions of each inflow from edges in the first tree can be expressed in the following two general equations:
or
The derivation of the conditional marginal distributions of each inflow from edges in other trees can be expressed in the following two general equations:
or
where
is an n-dimensional vector,
is any variable in
, and
is the vector composed of the remaining (n-1) variables.
- 4.
Selection of vine copula structures and derivation of joint distributions among multi-inflow.
Vine copula structures are flexible and numerous, and even for a canonical vine copula or D-vine copula, there are in total
d! structures on
d inflows [
40]. The vine structures can be determined by the sequential maximum spanning tree optimization method [
26]. This method looks for the tree with the maximal sum of weights under the assumption that the higher the sum of weights, the better the goodness-of-fit [
41]. Since the weights of trees represent the goodnesses-of-fit, the opposites of the AIC values are chosen as weights, i.e.,
where
T is the index of trees in the vine copula functions, and
N is the index of edges in the trees.
The derivation of joint distributions among multi-inflow from vine copula structures can be expressed in the following equation:
where
represents the
i-th variable (
i = 1, 2, …,
d − 2) in
. The joint distribution of the three variables as shown in
Figure 5a can be expressed in the following equation:
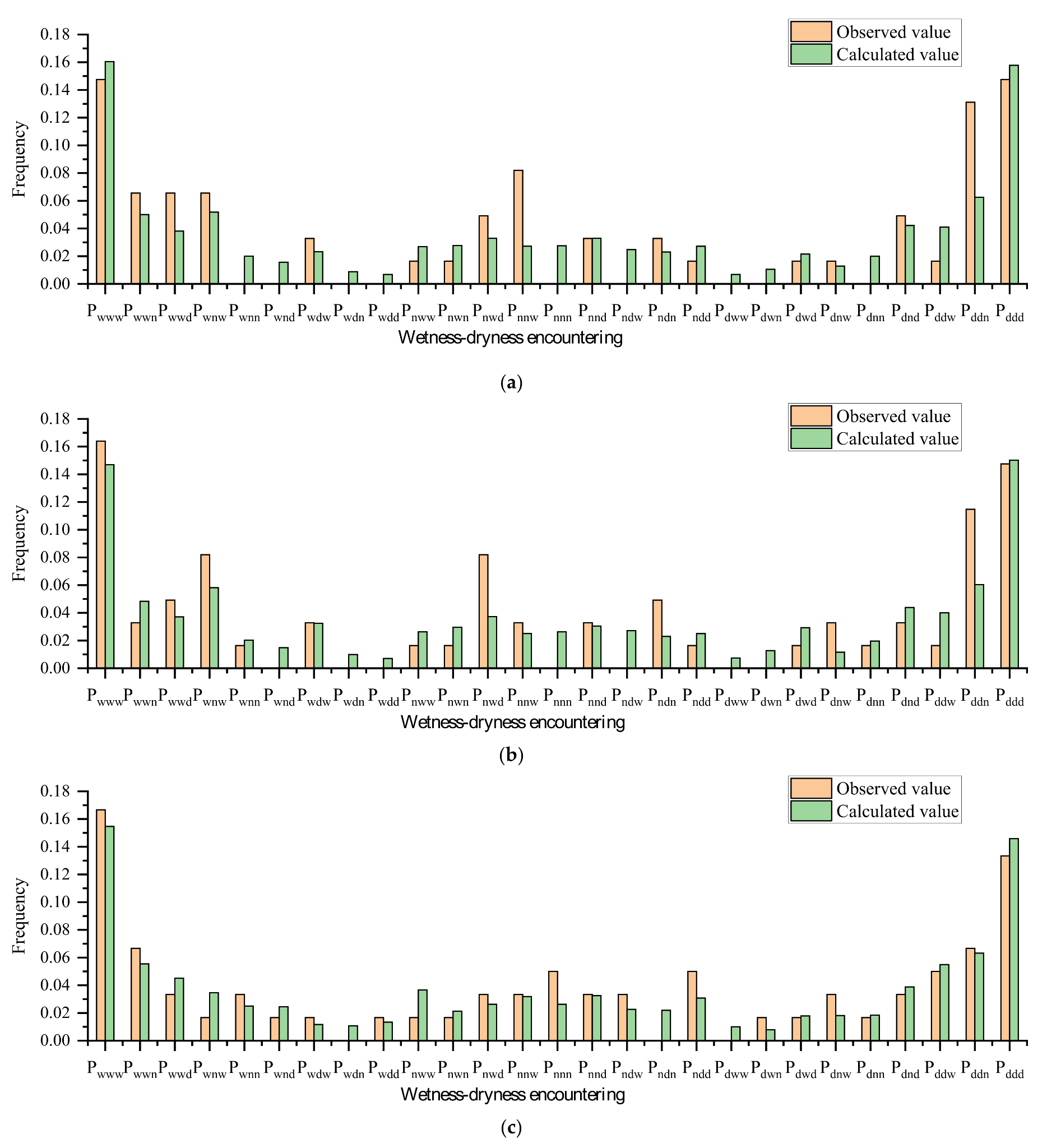
3.2.3. Forecasting for the Probability of Wetness-Dryness Encountering
The probability of wetness-dryness encountering is forecast from the historical statistical probability of wetness-dryness encountering in addition to forecasting information of some water systems by Bayesian networks. Based on the conditional probability formula and Bayes’ theorem, Bayesian networks [
29] are directed acyclic graphs with a mesh structure, which abstract random events into nodes of a network, and connect nodes with related relationships by directed arcs in order to graphically express the probabilities of random events as well as visualize the interactions between the elements. Bayes’ theorem was summarized by mathematician Bayes, in order to describe the relationship between conditional probabilities. Its main content is as follows: in a test, the sample space is
S,
A is the event of the test, and
is the division of the sample space
S. Then, the probability is obtained as follows:
Bayesian networks consist of two parts: network structure and network parameters. The network structure refers to the topology established according to the causal relationship between nodes, which is generally expressed through a directed acyclic graph; the network parameters are the prior probability of the root nodes and the conditional probability of the non-root nodes, which are generally calculated according to the conditional probability table.
The main steps of forecasting for the probability of wetness-dryness encountering using Bayesian networks are as follows:
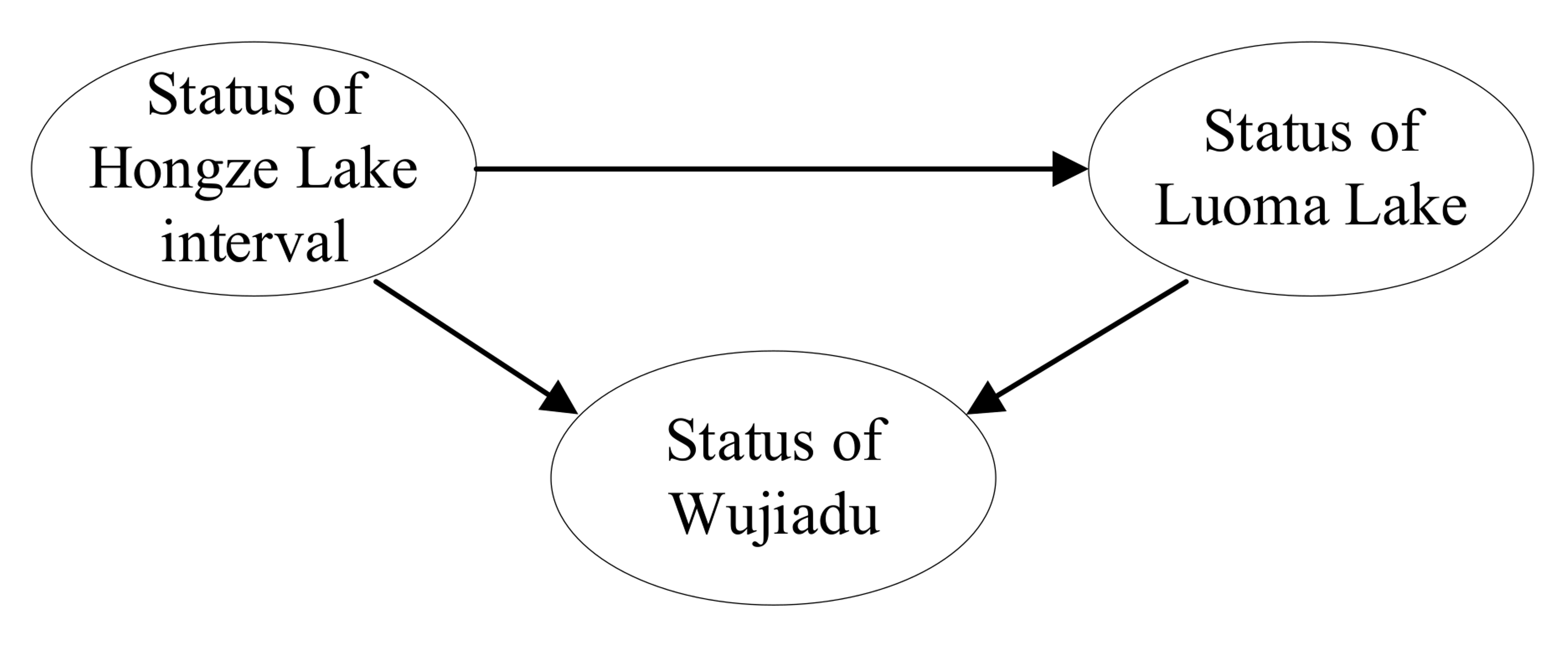
Construction of a directed acyclic graph, i.e., the structure of the Bayesian network, based on the actual problem.
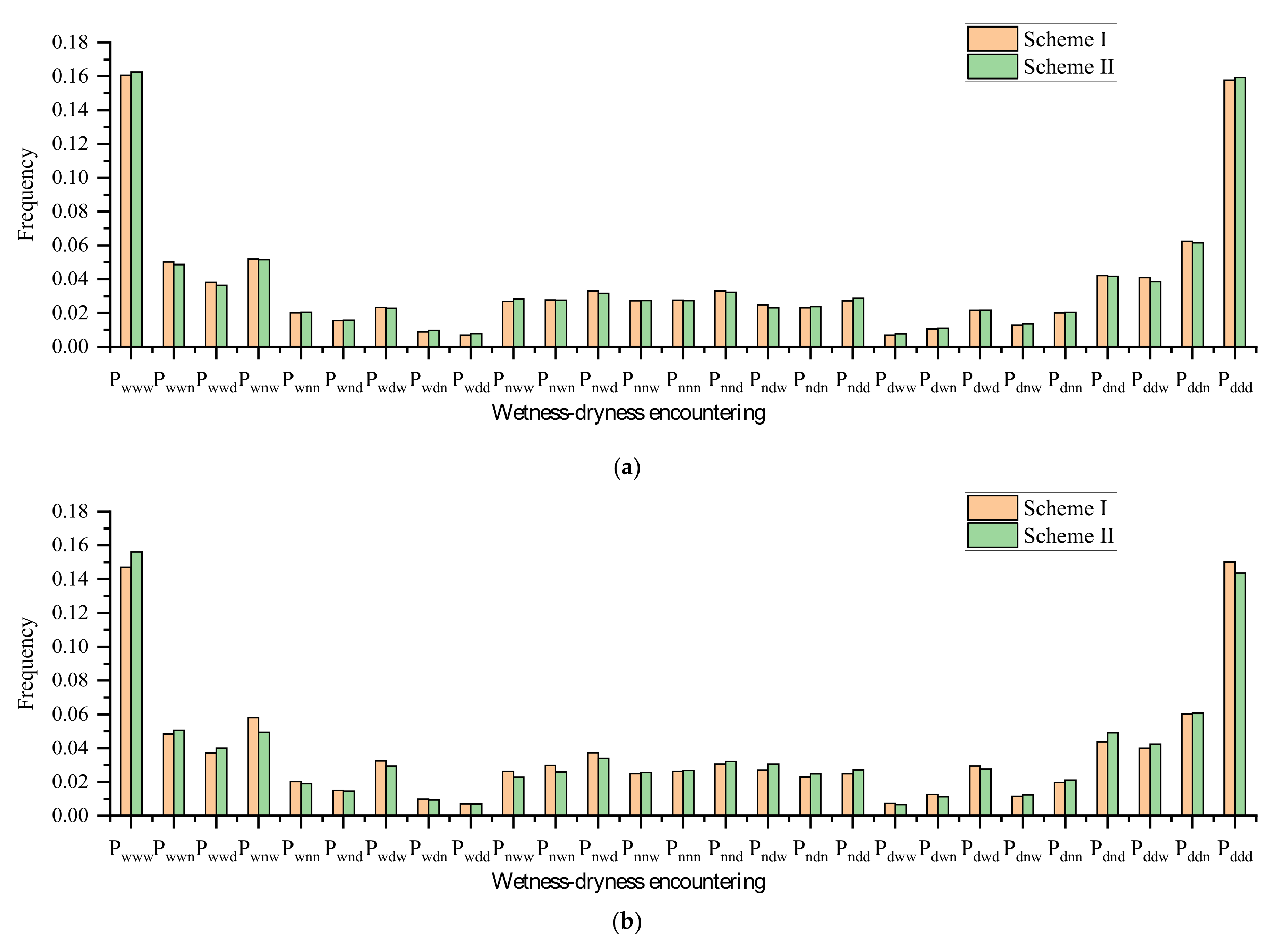
Calculation for the conditional probability table. From the historical statistical probabilities of wetness-dryness encountering calculated in
Section 3.2.2, the conditional probability table can be derived according to the conditional probability formula.
Input forecasting information of some water systems into the Bayesian network, and the probability of wetness-dryness encountering in the future period can be obtained by the Bayesian network.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}