
Mid- to Long-Term Runoff Prediction Based on Deep Learning at Different Time Scales in the Upper Yangtze River Basin

 , , and
, , and
Abstract
:1. Introduction
2. Study Area and Data
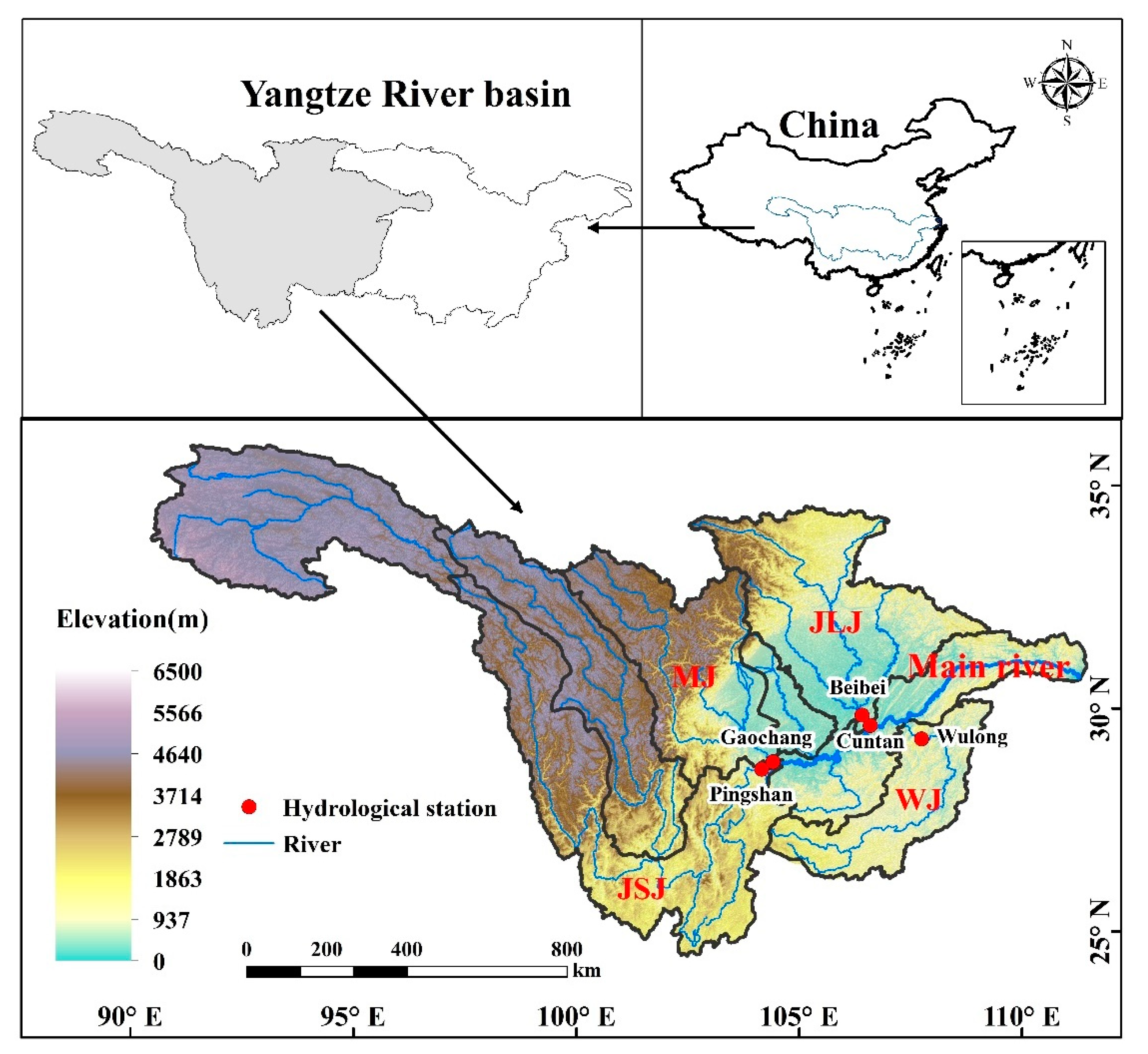
2.1. Study Area
2.2. Data Preprocessing
3. Methods
3.1. Deep Learning Methodology for Mid- to Long-Term Runoff Prediction
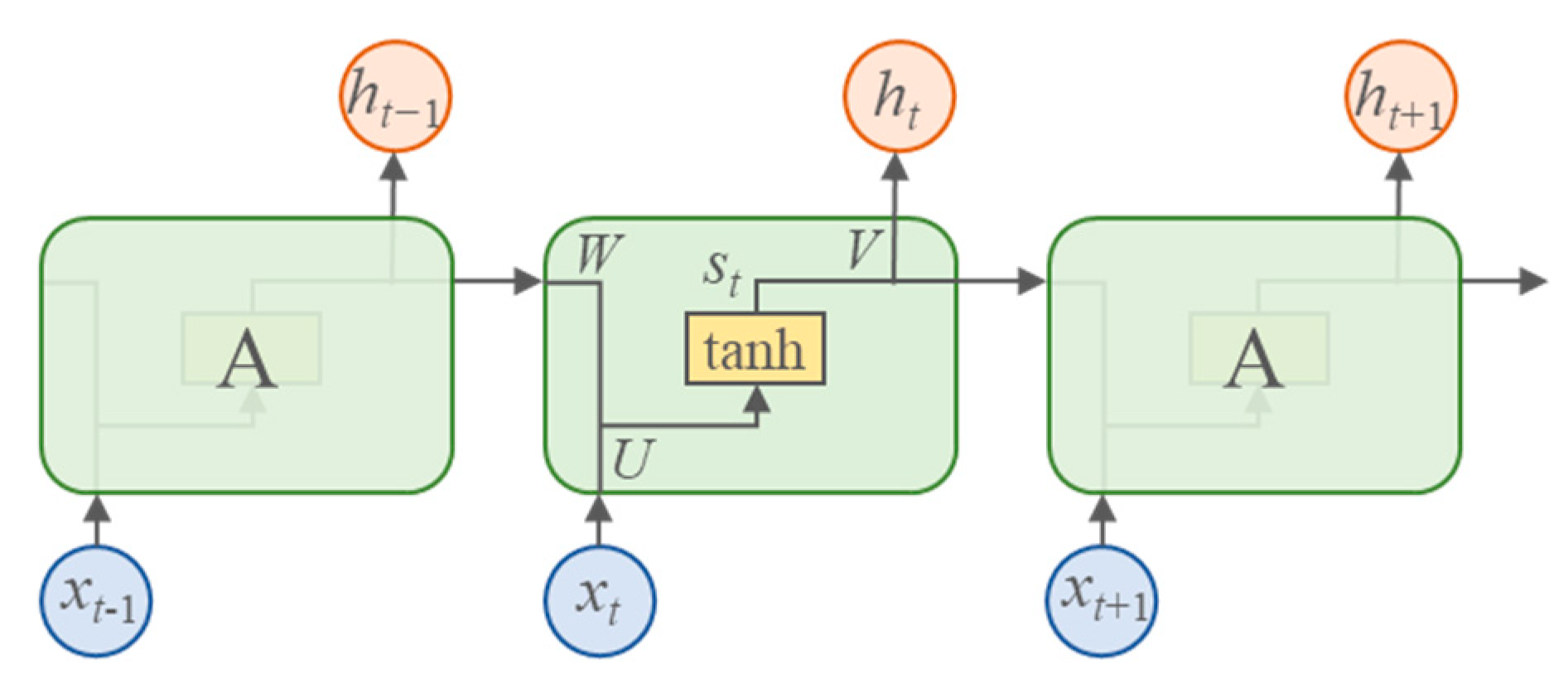
3.1.1. Recurrent Neural Network (RNN)
3.1.2. Long–Short-Term Memory (LSTM)
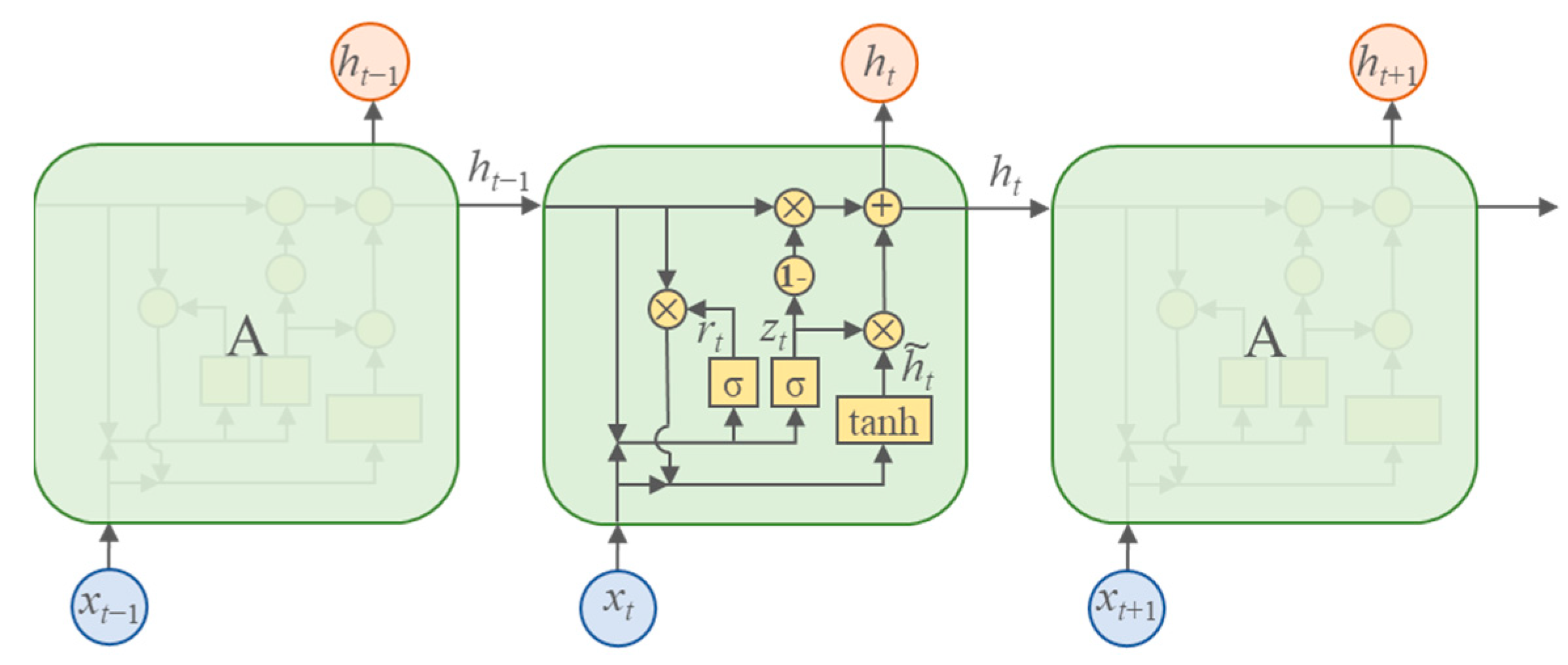
3.1.3. Gated Recurrent Unit (GRU)
3.2. Model Calculation Schemes
3.3. Formatting of Mathematical Components
4. Results and Discussions
4.1. Daily Runoff Prediction
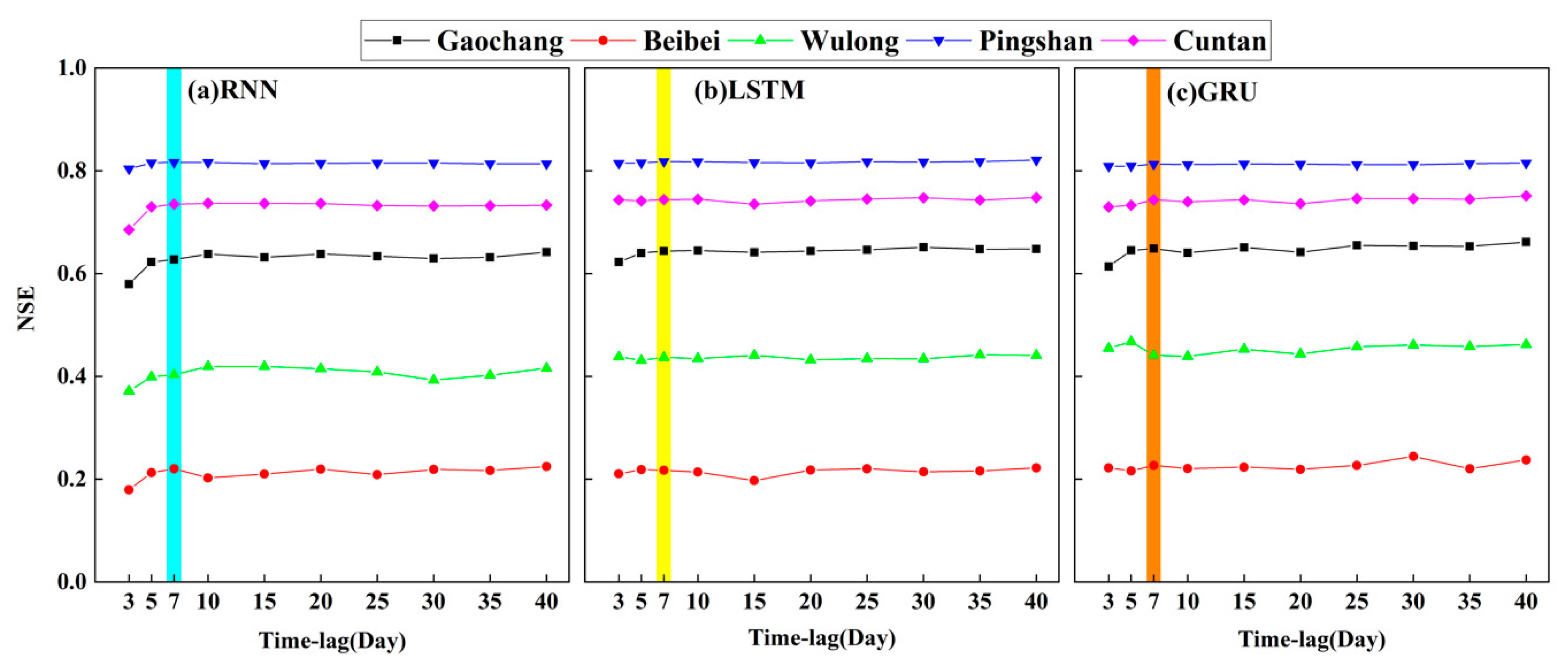
4.1.1. Performance Comparison among the RNN, LSTM, and GRU Models with Different Time Lags in Daily Runoff Prediction
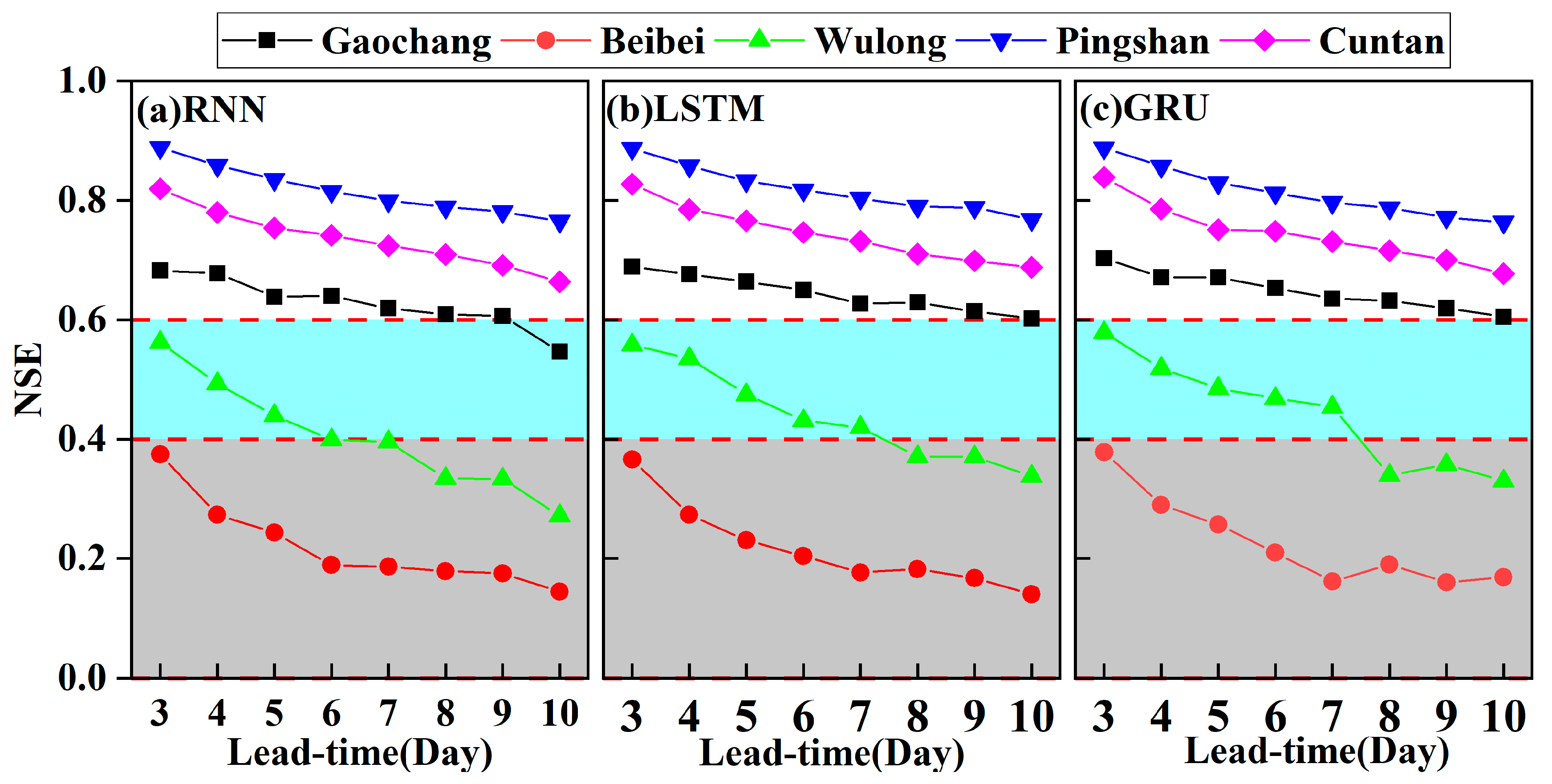
4.1.2. Multi-Day-Ahead Runoff Prediction
4.1.3. Modeling Parameter Optimization in Daily Runoff Prediction
4.2. Ten-Day Runoff Prediction
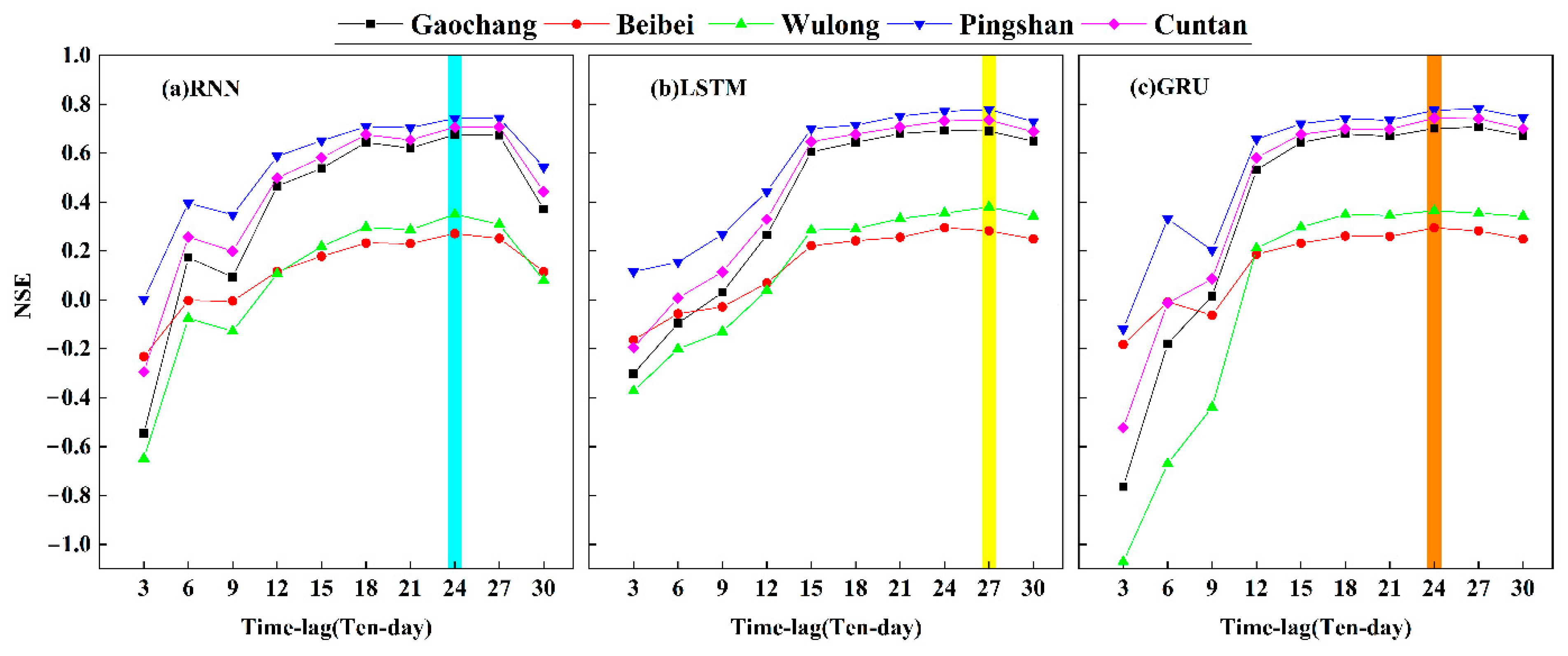
4.2.1. Performance Comparison among the RNN, LSTM, and GRU Models with Different Time Lags in Ten-Day Runoff Prediction
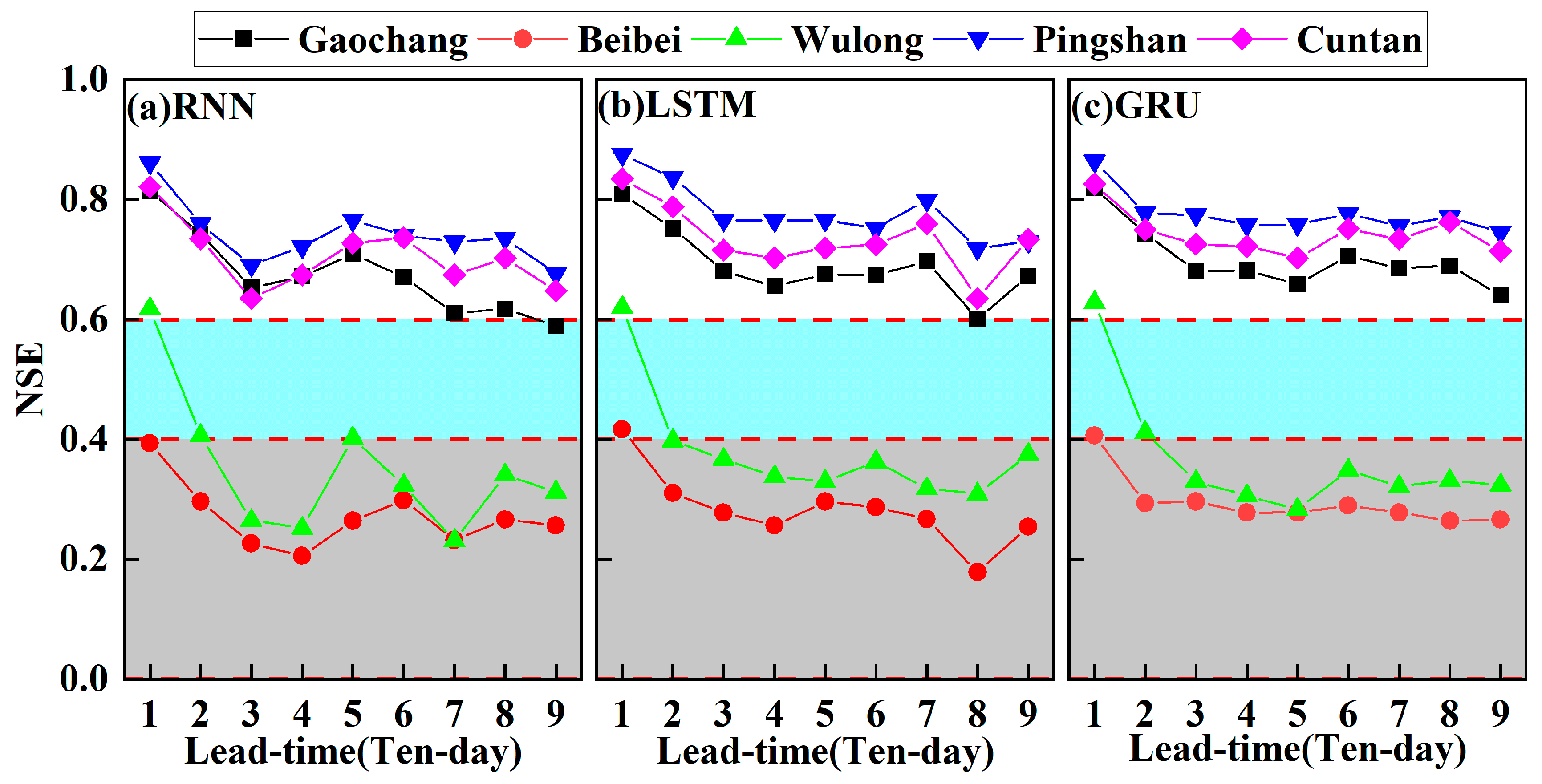
4.2.2. Multi-Ten-Day-Ahead Runoff Prediction
4.2.3. Modeling Parameter Optimization in Ten-Day Runoff Prediction
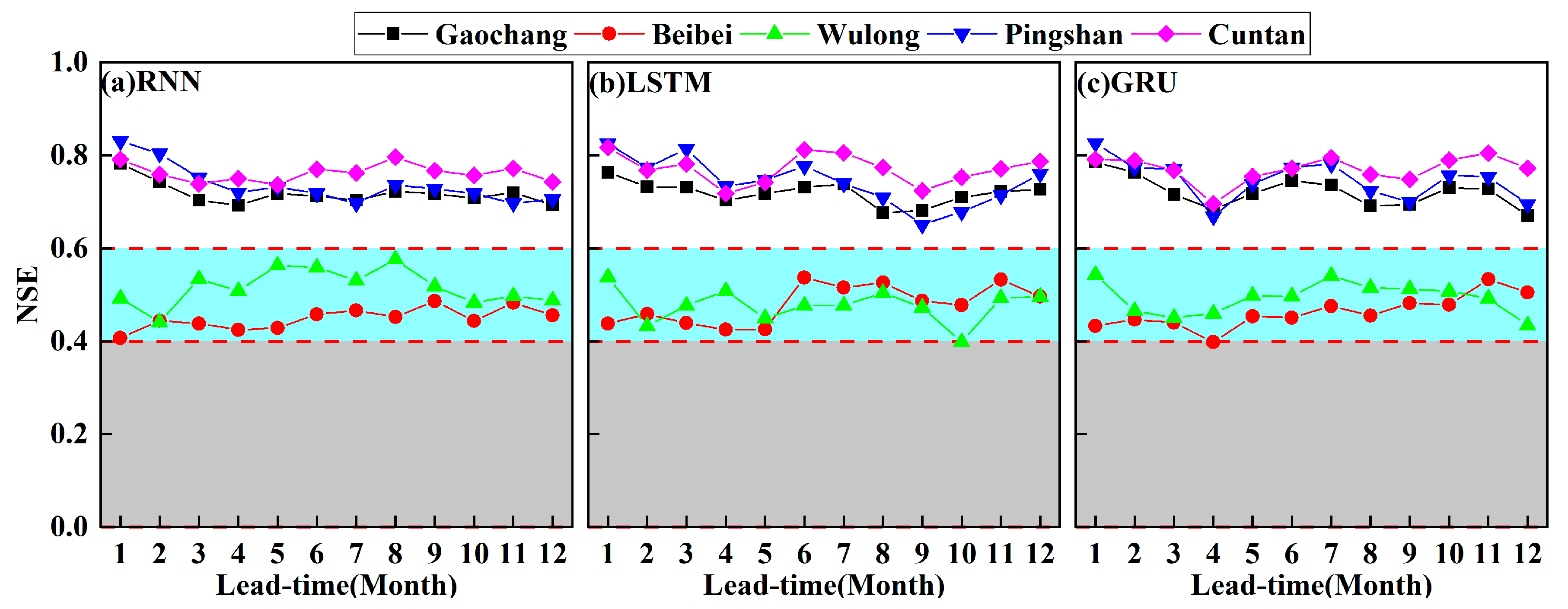
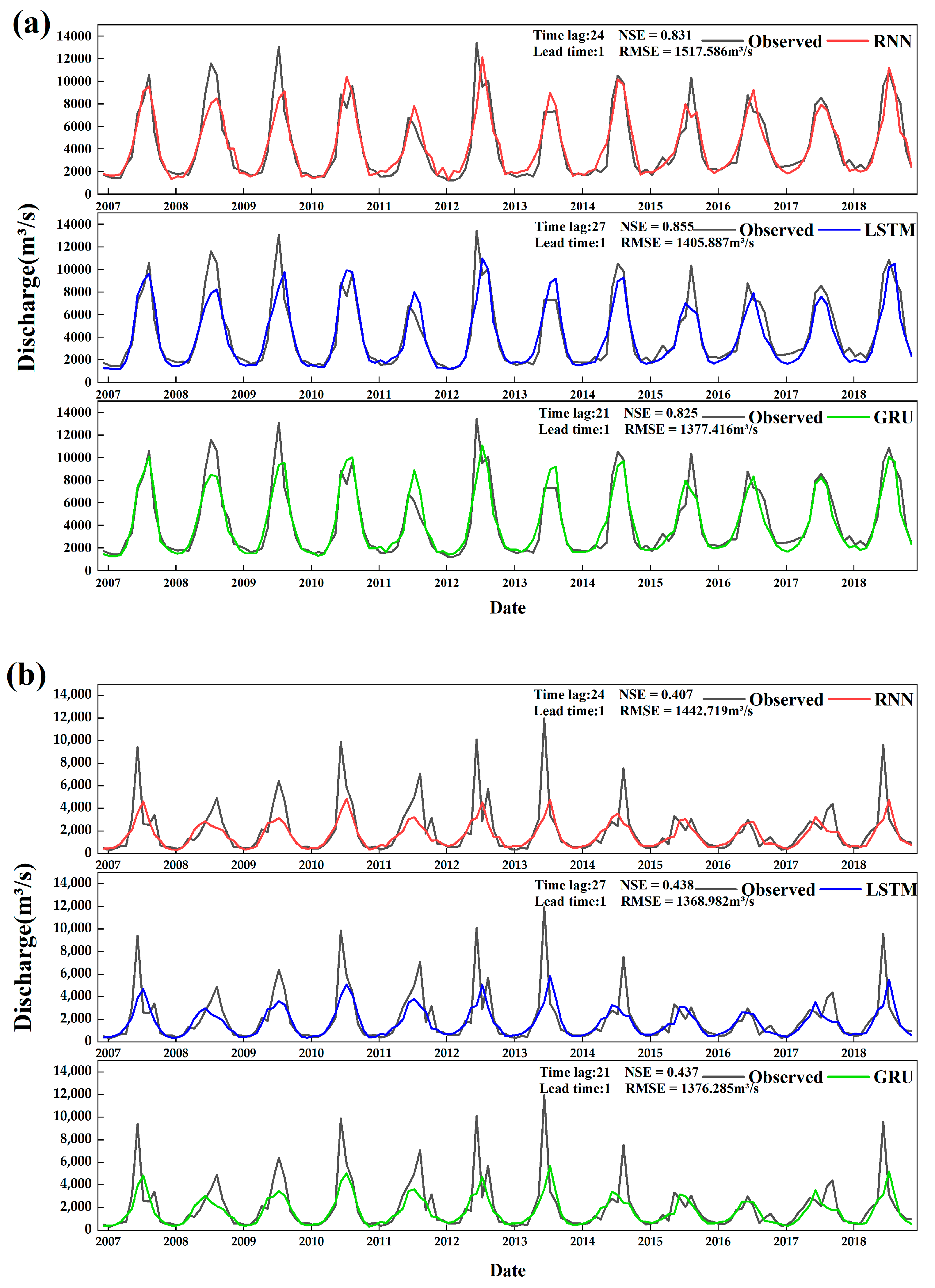
4.3. Monthly Runoff Prediction
4.3.1. Performance Comparison among the RNN, LSTM, and GRU Models with Different Time Lags in Monthly Runoff Prediction
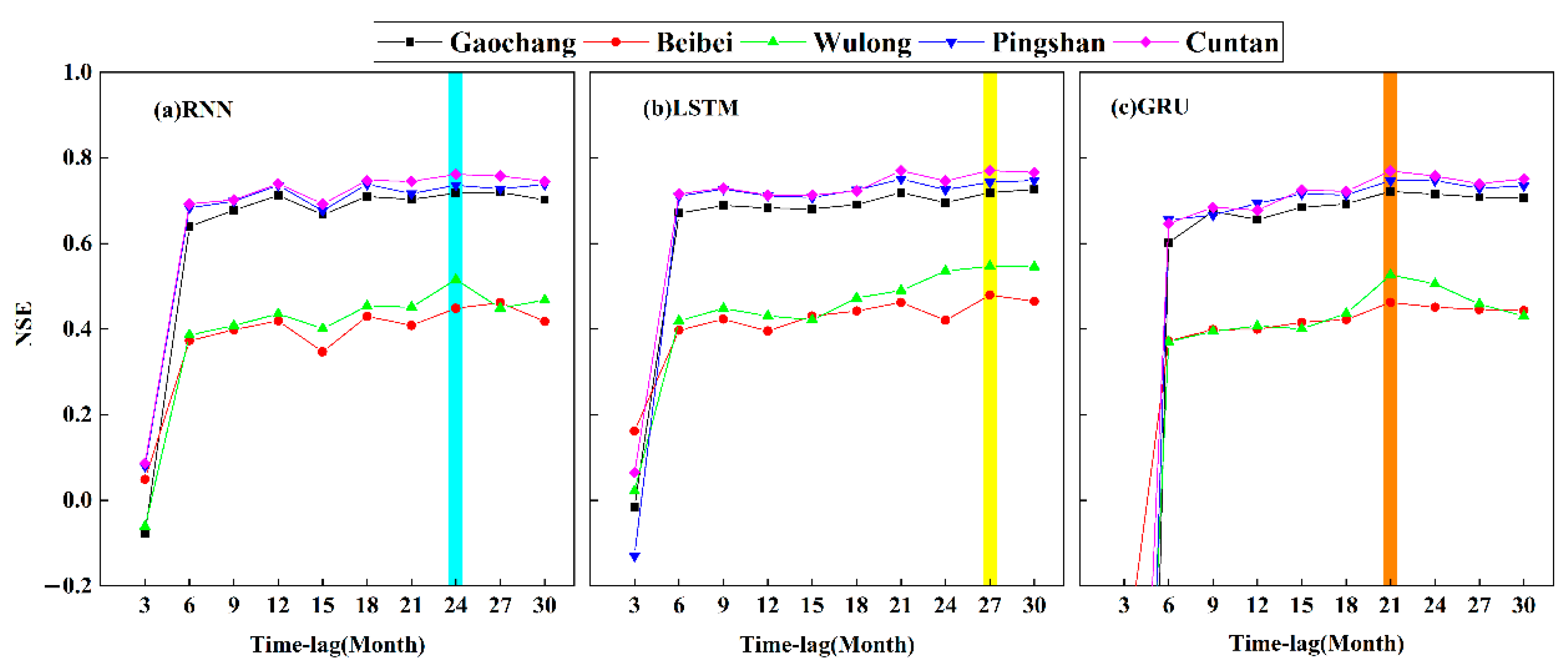
4.3.2. Multi-Month-Ahead Runoff Prediction
4.3.3. Modeling Parameter Optimization in Monthly Runoff Prediction
4.4. Comparison of the Runoff Prediction at Different Time Scales
5. Conclusions
- (1)
- In daily runoff prediction, the optimal time lag was 7 days, and the optimal lead time was 3 days in RNN, LSTM, and RNN models. The prediction process of runoff achieved a good relationship with observation in optimal parameters settings. However, the models still had significant shortcomings in predicting high discharge.
- (2)
- In ten-day runoff prediction, the time lags of RNN, LSTM, and GRU models, respectively, were set to 24, 27, and 24 ten-days, and we set the lead time of 1 ten day as that which would have the best results. However, the three models proved hard to capture the high discharge at the process of ten-day runoff.
- (3)
- In monthly runoff prediction, the optimal time-lags were 24, 27, and 21 months, and optimal lead time was 1 month of RNN, LSTM, and GRU models. Although the three models were well-simulated with observed discharge at monthly runoff prediction, it was hard to accurately capture the low and high discharge.
- (4)
- The length of time lag and the lead time greatly impacted the results of RNN, LSTM, and GRU models at daily, ten-day, monthly runoff prediction. With the increase of time lags, the simulation accuracy stabilized after a specific time lag at multiple time scales of runoff prediction. Increased lead time was linearly related to decreased NSE at daily and ten-day runoff prediction. However, there was no significant linear relationship between NSE and lead time at monthly runoff prediction. The RMSE of the three models revealed that RNN was inferior to LSTM and GRU in runoff prediction. In addition, RNN, LSTM, and GRU models could not accurately predict extreme runoff events at different time scales.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mosavi, A.; Ozturk, P.; Chau, K. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef] [Green Version]
- You, G.J.; Thum, B.; Lin, F. The examination of reproducibility in hydro-ecological characteristics by daily synthetic flow models. J. Hydrol. 2014, 511, 904–919. [Google Scholar] [CrossRef]
- Bai, H.; Li, G.; Liu, C.; Li, B.; Zhang, Z.; Qin, H. Hydrological probabilistic forecasting based on deep learning and Bayesian optimization algorithm. Hydrol. Res. 2021, 52, 927–943. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, X.; Corbari, C.; Mancini, M.; Niu, G.; Zeng, W. Improving the Xin’anjiang hydrological model based on mass–energy balance. Hydrol. Earth Syst. Sci. 2017, 21, 3359–3375. [Google Scholar] [CrossRef] [Green Version]
- Gautam, S.; Costello, C.; Baffaut, C.; Thompson, A.; Svoma, B.; Phung, Q.; Sadler, E. Assessing Long-Term hydrological impact of climate change using an ensemble approach and comparison with global gridded Model-A case study on good Water creek experimental Watershed. Water 2018, 10, 564. [Google Scholar] [CrossRef] [Green Version]
- Troin, M.; Arsenault, R.; Wood, A.W.; Brissette, F.; Martel, J.L. Generating ensemble streamflow forecasts: A review of methods and approaches over the past 40 years. Water Resour. Res. 2021, 57, e2020WR028392. [Google Scholar] [CrossRef]
- Graeff, T.; Zehe, E.; Blume, T.; Francke, T.; Schröder, B. Predicting event response in a nested catchment with generalized linear models and a distributed Watershed model. Hydrol. Process 2012, 26, 3749–3769. [Google Scholar] [CrossRef]
- Valizadeh, N.; Mirzaei, M.; Allawi, M.F.; Afan, H.A.; Mohd, N.S.; Hussain, A.; El-Shafie, A. Artificial intelligence and geostatistical models for stream-flow forecasting in ungauged stations: State of the art. Nat. Hazards 2017, 86, 1377–1392. [Google Scholar] [CrossRef]
- Gao, Y.; Yuan, Y.; Wang, H.; Schmidt, A.R.; Wang, K.; Ye, L. Examining the effects of urban agglomeration polders on flood events in Qinhuai River basin, China with HEC-HMS model. Water Sci. Technol. 2017, 75, 2130–2138. [Google Scholar] [CrossRef]
- Chen, Y.; Gao, J.; Bin, Z.; Qian, J.; Pei, R.; Zhu, H. Application study of IFAS and LSTM models on runoff simulation and flood prediction in the Tokachi River basin. J. Hydroinform. 2021, 23, 1098–1111. [Google Scholar] [CrossRef]
- Rujner, H.; Leonhardt, G.; Marsalek, J.; Viklander, M. High-resolution modelling of the grass swale response to runoff inflows with Mike SHE. J. Hydrol. 2018, 562, 411–422. [Google Scholar] [CrossRef]
- Li, C.; Zhu, L.; He, Z.; Gao, H.; Yang, Y.; Yao, D.; Qu, X. Runoff Prediction Method Based on Adaptive Elman Neural Network. Water 2019, 11, 1113. [Google Scholar] [CrossRef] [Green Version]
- Kan, G.; Yao, C.; Li, Q.; Li, Z.; Yu, Z.; Liu, Z.; Ding, L.; He, X.; Liang, K. Improving event-based rainfall-runoff simulation using an ensemble artificial neural network based hybrid data-driven model. Stoch. Environ. Res. Risk. A 2015, 29, 1345–1370. [Google Scholar] [CrossRef]
- Amin, S.; Van Moer, W.; Handel, P.; Ronnow, D. Characterization of concurrent Dual-Band power amplifiers using a dual Two-Tone excitation signal. IEEE T. Instrum. Meas. 2015, 64, 2781–2791. [Google Scholar] [CrossRef]
- Elshorbagy, A.; Corzo, G.; Srinivasulu, S.; Solomatine, D.P. Experimental investigation of the predictive capabilities of data driven modeling techniques in hydrology-Part 2: Application. Hydrol. Earth. Syst. Sci. 2010, 14, 1943–1961. [Google Scholar] [CrossRef] [Green Version]
- Muñoz, P.; Orellana-Alvear, J.; Willems, P.; Célleri, R. Flash-Flood forecasting in an andean mountain catchment—Development of a Step-Wise methodology based on the random forest algorithm. Water 2018, 10, 1519. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Kang, L.; Zhou, L.; Zhu, M. Deep learning framework with time series analysis methods for runoff prediction. Water 2021, 13, 575. [Google Scholar] [CrossRef]
- Bergen, K.J.; Johnson, P.A.; de Hoop, M.V.; Beroza, G.C. Machine learning for data-driven discovery in solid Earth geoscience. Science 2019, 363, eaau0323. [Google Scholar] [CrossRef]
- Shi, B.; Hu, C.H.; Yu, X.H.; Hu, X.X. New fuzzy neural network-Markov model and application in mid-to long-term runoff forecast. Hydrol. Sci. J. 2016, 61, 1157–1169. [Google Scholar] [CrossRef] [Green Version]
- Sharafati, A.; Tafarojnoruz, A.; Shourian, M.; Yaseen, Z.M. Simulation of the depth scouring downstream sluice gate: The validation of newly developed data-intelligent models. J. Hydro-Environ. Res. 2020, 29, 20–30. [Google Scholar] [CrossRef]
- Li, H.; Tian, L.; Wu, Y.; Xie, M. Improvement of mid-to long-term runoff forecasting based on physical causes: Application in Nenjiang basin, China. Hydrol. Sci. J. 2013, 58, 1414–1422. [Google Scholar] [CrossRef] [Green Version]
- Chu, H.; Wei, J.; Li, T.; Jia, K. Application of support vector regression for mid-and long-term runoff forecasting in “yellow river headWater” region. Procedia Eng. 2016, 154, 1251–1257. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Chen, X.; Khan, A.; Zhang, Y.; Kuang, X.; Liang, X.; Taccari, M.L.; Nuttall, J. Daily runoff forecasting by deep recursive neural network. J. Hydrol. 2021, 596, 126067. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, J.; Liu, R.; Men, C.; Guo, L.; Miao, Y.; Jiao, L.; Wang, Y.; Shoaib, M.; Xia, X. Sequence-based statistical downscaling and its application to hydrologic simulations based on machine learning and big data. J. Hydrol. 2020, 586, 124875. [Google Scholar] [CrossRef]
- Xie, K.; Liu, P.; Zhang, J.; Han, D.; Wang, G.; Shen, C. Physics-guided deep learning for rainfall-runoff modeling by considering extreme events and monotonic relationships. J. Hydrol. 2021, 603, 127043. [Google Scholar] [CrossRef]
- Mao, G.; Wang, M.; Liu, J.; Wang, Z.; Wang, K.; Meng, Y.; Zhong, R.; Wang, H.; Li, Y. Comprehensive comparison of artificial neural networks and long short-term memory networks for rainfall-runoff simulation. Phys. Chem. Earth Parts A/B/C 2021, 123, 103026. [Google Scholar] [CrossRef]
- Thapa, S.; Li, H.; Li, B.; Fu, D.; Shi, X.; Yabo, S.; Lu, L.; Qi, H.; Zhang, W. Impact of climate change on snowmelt runoff in a Himalayan basin, Nepal. Environ. Monit. Assess. 2021, 193, 1–17. [Google Scholar] [CrossRef]
- Zhang, D.; Peng, Q.; Lin, J.; Wang, D.; Liu, X.; Zhuang, J. Simulating reservoir operation using a recurrent neural network algorithm. Water 2019, 11, 865. [Google Scholar] [CrossRef] [Green Version]
- Moazami Goudarzi, F.; Sarraf, A.; Ahmadi, H. Prediction of runoff within Maharlu basin for future 60 years using RCP scenarios. Arab. J. Geosci. 2020, 13, 605. [Google Scholar] [CrossRef]
- Feng, Z.; Niu, W.; Tang, Z.; Jiang, Z.; Xu, Y.; Liu, Y.; Zhang, H. Monthly runoff time series prediction by variational mode decomposition and support vector machine based on quantum-behaved particle swarm optimization. J. Hydrol. 2020, 583, 124627. [Google Scholar] [CrossRef]
- Nonki, R.M.; Lenouo, A.; Tshimanga, R.M.; Donfack, F.C.; Tchawoua, C. Performance assessment and uncertainty prediction of a daily time-step HBV-Light rainfall-runoff model for the Upper Benue River Basin, Northern Cameroon. J. Hydrol. Reg. Stud. 2021, 36, 100849. [Google Scholar] [CrossRef]
- Li, Y.; Wei, J.; Wang, D.; Li, B.; Huang, H.; Xu, B.; Xu, Y. A medium and Long-Term runoff forecast method based on massive meteorological data and machine learning algorithms. Water 2021, 13, 1308. [Google Scholar] [CrossRef]
- Han, H.; Choi, C.; Jung, J.; Kim, H.S. Deep learning with long short term memory based Sequence-to-Sequence model for Rainfall-Runoff simulation. Water 2021, 13, 437. [Google Scholar] [CrossRef]
- Moghadam, S.V.; Sharafati, A.; Feizi, H.; Marjaie, S.M.S.; Asadollah, S.B.H.S.; Motta, D. An efficient strategy for predicting river dissolved oxygen concentration: Application of deep recurrent neural network model. Environ. Monit Assess. 2021, 193, 798. [Google Scholar] [CrossRef]
- Chen, X.; Huang, J.; Wang, S.; Zhou, G.; Gao, H.; Liu, M.; Yuan, Y.; Zheng, L.; Li, Q.; Qi, H. A new Rainfall-Runoff model using improved LSTM with attentive long and short Lag-Time. Water 2022, 14, 697. [Google Scholar] [CrossRef]
- Chen, X.; Huang, J.; Han, Z.; Gao, H.; Liu, M.; Li, Z.; Liu, X.; Li, Q.; Qi, H.; Huang, Y.; et al. The importance of short lag-time in the runoff forecasting model based on long short-term memory. J. Hydrol. 2020, 589, 125359. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, S.; Han, J.; Wang, G.; Zhang, M.; Lin, Q. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Yue, Z.; Ai, P.; Xiong, C.; Hong, M.; Song, Y. Mid-to long-term runoff prediction by combining the deep belief network and partial least-squares regression. J. Hydroinform. 2020, 22, 1283–1305. [Google Scholar] [CrossRef]
- Ji, Y.; Dong, H.; Xing, Z.; Sun, M.; Fu, Q.; Liu, D. Application of the decomposition-prediction-reconstruction framework to medium- and long-term runoff forecasting. Water Supply. 2021, 21, 696–709. [Google Scholar] [CrossRef]
- Zhao, X.; Lv, H.; Lv, S.; Sang, Y.; Wei, Y.; Zhu, X. Enhancing robustness of monthly streamflow forecasting model using gated recurrent unit based on improved grey wolf optimizer. J. Hydrol. 2021, 601, 126607. [Google Scholar] [CrossRef]
- Zhong, W.; Guo, J.; Chen, L.; Zhou, J.; Zhang, J.; Wang, D. Future hydropower generation prediction of large-scale reservoirs in the upper Yangtze River basin under climate change. J. Hydrol. 2020, 588, 125013. [Google Scholar] [CrossRef]
- Xiao, Z.; Shi, P.; Jiang, P.; Hu, J.; Qu, S.; Chen, X.; Chen, Y.; Dai, Y.; Wang, J. The spatiotemporal variations of runoff in the yangtze river basin under climate change. Adv. Meteorol. 2018, 2018, 5903451. [Google Scholar] [CrossRef] [Green Version]
- Su, B.; Huang, J.; Zeng, X.; Gao, C.; Jiang, T. Impacts of climate change on streamflow in the upper Yangtze River basin. Clim. Change 2017, 141, 533–546. [Google Scholar] [CrossRef]
- Wang, Z.; Qiu, J.; Li, F. Hybrid models combining EMD/EEMD and ARIMA for Long-Term streamflow forecasting. Water 2018, 10, 853. [Google Scholar] [CrossRef] [Green Version]
- Elganiny, M.A.; Eldwer, A.E. Enhancing the forecasting of monthly streamflow in the main key stations of the river Nile basin. Water Resour. Regime Water Bodies 2018, 5, 660–671. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, Y.; Tian, S.; Lai, S. Forecasting Rainfall with Recurrent Neural Network for irrigation equipment. IOP conference series. Earth Environ. Sci. 2020, 510, 42040. [Google Scholar] [CrossRef]
- Nguyen, V.Q.; Anh, T.N.; Yang, H. Real-time event detection using recurrent neural network in social sensors. Int. J. Distrib. Sens. Netw. 2019, 15, 812338417. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M. Yang J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Ahmed, N.; Campbell, M. Variational bayesian learning of probabilistic discriminative models with latent softmax variables. IEEE Trans. Signal Processing 2011, 59, 3143–3154. [Google Scholar] [CrossRef]
- Totaro, S.; Hussain, A.; Scardapane, S. A non-parametric softmax for improving neural attention in time-series forecasting. Neurocomputing 2020, 381, 177–185. [Google Scholar] [CrossRef]
- Geng, Z.; Chen, G.; Han, Y.; Lu, G.; Li, F. Semantic relation extraction using sequential and tree-structured LSTM with attention. Inform. Sci. 2020, 509, 183–192. [Google Scholar] [CrossRef]
- Liu, X.; Zeng, Z.; Wunsch, D.C., II. Memristor-based LSTM network with in situ training and its applications. Neural Netw. 2020, 131, 300–311. [Google Scholar] [CrossRef] [PubMed]
- Ayzel, G.; Heistermann, M. The effect of calibration data length on the performance of a conceptual hydrological model versus LSTM and GRU: A case study for six basins from the CAMELS dataset. Comput. Geosci. 2021, 149, 104708. [Google Scholar] [CrossRef]
- Thapa, S.; Zhao, Z.; Li, B.; Lu, L.; Fu, D.; Shi, X.; Tang, B.; Qi, H. Snowmelt-Driven streamflow prediction using machine learning techniques (LSTM, NARX, GPR, and SVR). Water 2020, 12, 1734. [Google Scholar] [CrossRef]
- Sharafati, A.; Tafarojnoruz, A.; Motta, D.; Yaseen, Z.M. Application of nature-inspired optimization algorithms to ANFIS model to predict wave-induced scour depth around pipelines. J. Hydroinform. 2020, 22, 1425–1451. [Google Scholar] [CrossRef]
- Sharafati, A.; Tafarojnoruz, A. Yaseen Z M. New stochastic modeling strategy on the prediction enhancement of pier scour depth in cohesive bed materials. J. Hydroinform. 2020, 22, 457–472. [Google Scholar] [CrossRef]
- Ishida, K.; Kiyama, M.; Ercan, A.; Amagasaki, M.; Tu, T. Multi-time-scale input approaches for hourly-scale rainfall–runoff modeling based on recurrent neural networks. J. Hydroinform. 2021, 23, 1312–1324. [Google Scholar] [CrossRef]
- Li, W.; Kiaghadi, A.; Dawson, C. Exploring the best sequence LSTM modeling architecture for flood prediction. Neural Comput. Appl. 2021, 33, 5571–5580. [Google Scholar] [CrossRef]
- Cheng, M.; Fang, F.; Kinouchi, T.; Navon, I.M.; Pain, C.C. Long lead-time daily and monthly streamflow forecasting using machine learning methods. J. Hydrol. 2020, 590, 125376. [Google Scholar] [CrossRef]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep learning with a long Short-Term memory networks approach for Rainfall-Runoff simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef] [Green Version]
- Callegari, M.; Mazzoli, P.; de Gregorio, L.; Notarnicola, C.; Pasolli, L.; Petitta, M.; Pistocchi, A. Seasonal river discharge forecasting using support vector regression: A case study in the italian alps. Water 2015, 7, 2494–2515. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Tian, D.; Lowe, L.; Kalin, L.; Lehrter, J. Deep learning for daily precipitation and temperature downscaling. Water Resour. Res. 2021, 57, e2020WR029308. [Google Scholar] [CrossRef]
- Baño-Medina, J.; Manzanas, R.; Gutiérrez, J.M. Configuration and intercomparison of deep learning neural models for statistical downscaling. Geosci. Model Dev. 2020, 13, 2109–2124. [Google Scholar] [CrossRef]
- Fang, W.; Xue, Q.; Shen, L.; Sheng, V.S. Survey on the application of deep learning in extreme weather prediction. Atmosphere 2021, 12, 661. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, T.; Kang, A.; Li, J.; Lei, X. Research on Runoff Simulations Using Deep-Learning Methods. Sustainability 2021, 13, 1336. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, J.; Yao, L.; Guo, P.; Yuan, Z. The land use pattern and its changes in the upper reaches of the Yangtze River from 1980 to 2015. IOP conference series. Earth Environ. Sci. 2021, 676, 12097. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, M.; Song, Y.; Lai, Y. Hydrological simulation of the Jialing River Basin using the MIKE SHE model in changing climate. J. Water Clim. Change 2021, 12, 2495–2514. [Google Scholar] [CrossRef]
- Wu, X.; Xiang, X.; Chen, X.; Zhang, X.; Hua, W. Effects of cascade reservoir dams on the streamflow and sediment transport in the Wujiang River basin of the Yangtze River, China. Inland Waters Print 2018, 8, 216–228. [Google Scholar] [CrossRef]
- Li, S.; Xiong, L.; Li, H.; Leung, L.R.; Demissie, Y. Attributing runoff changes to climate variability and human activities: Uncertainty analysis using four monthly Water balance models. Stoch. Environ. Res. Risk A 2016, 30, 251–269. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, Y.; Guo, H.; He, D. Combining the SWAT model with sequential uncertainty fitting algorithm for streamflow prediction and uncertainty analysis for the Lake Dianchi Basin, China. Hydrol. Process 2014, 28, 521–533. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pingshan | Beibei | Wulong | Gaochang | |
|---|---|---|---|---|
| Longitude | 104.16 | 106.42 | 107.75 | 104.42 |
| Latitude | 28.63 | 29.85 | 29.32 | 28.8 |
| Catchment area (km2) | 458,592 | 156,142 | 83,035 | 135,378 |
| Scale | Parameter | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Daily | Time lag | 3 | 5 | 7 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | ||
| Lead time | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||||
| Ten-day | Time lag | 3 | 6 | 9 | 12 | 15 | 18 | 21 | 24 | 27 | 30 | ||
| Lead time | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||||
| Monthly | Time lag | 3 | 6 | 9 | 12 | 15 | 18 | 21 | 24 | 27 | 30 | ||
| Lead time | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| Time-Lag (Day) | Mean NSE | |
|---|---|---|
| RNN | 7 | 0.560 |
| LSTM | 7 | 0.572 |
| GRU | 7 | 0.574 |
| Gaochang | Beibei | Wulong | Pingshan | Cuntan | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | |
| RNN | 0.682 | 1277.144 | 0.374 | 2415.775 | 0.562 | 1153.855 | 0.888 | 1000.388 | 0.819 | 3468.217 |
| LSTM | 0.689 | 1256.343 | 0.366 | 2408.034 | 0.558 | 1150.255 | 0.887 | 968.240 | 0.827 | 3348.614 |
| GRU | 0.703 | 1238.188 | 0.378 | 2393.691 | 0.579 | 1126.187 | 0.888 | 967.555 | 0.839 | 3282.597 |
| Time Lag (Ten-Day) | Mean NSE | |
|---|---|---|
| RNN | 24 | 0.549 |
| LSTM | 27 | 0.573 |
| GRU | 24 | 0.576 |
| Gaochang | Beibei | Wulong | Pingshan | Cuntan | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | |
| RNN | 0.814 | 871.792 | 0.393 | 1784.135 | 0.617 | 930.174 | 0.861 | 1353.233 | 0.821 | 3183.543 |
| LSTM | 0.809 | 819.733 | 0.417 | 1711.835 | 0.620 | 880.313 | 0.875 | 1306.992 | 0.834 | 3010.574 |
| GRU | 0.819 | 841.442 | 0.415 | 1749.562 | 0.629 | 902.709 | 0.864 | 1299.684 | 0.826 | 3096.534 |
| Time-Lag (Month) | Mean NSE | |
|---|---|---|
| RNN | 24 | 0.636 |
| LSTM | 27 | 0.652 |
| GRU | 21 | 0.646 |
| Gaochang | Beibei | Wulong | Pingshan | Cuntan | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | NSE | RMSE (m3/s) | |
| RNN | 0.782 | 723.898 | 0.407 | 1442.719 | 0.493 | 766.991 | 0.831 | 1517.586 | 0.791 | 3194.933 |
| LSTM | 0.783 | 716.806 | 0.438 | 1368.982 | 0.538 | 734.883 | 0.855 | 1405.887 | 0.816 | 2998.444 |
| GRU | 0.789 | 699.183 | 0.437 | 1376.285 | 0.587 | 739.440 | 0.825 | 1377.416 | 0.794 | 3022.717 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Zeng, S.; Liu, J.; Tang, Z.; Hua, X.; Li, Z.; Song, J.; Xia, J. Mid- to Long-Term Runoff Prediction Based on Deep Learning at Different Time Scales in the Upper Yangtze River Basin. Water 2022, 14, 1692. https://doi.org/10.3390/w14111692
Ren Y, Zeng S, Liu J, Tang Z, Hua X, Li Z, Song J, Xia J. Mid- to Long-Term Runoff Prediction Based on Deep Learning at Different Time Scales in the Upper Yangtze River Basin. Water. 2022; 14(11):1692. https://doi.org/10.3390/w14111692
Chicago/Turabian StyleRen, Yuanxin, Sidong Zeng, Jianwei Liu, Zhengyang Tang, Xiaojun Hua, Zhenghao Li, Jinxi Song, and Jun Xia. 2022. "Mid- to Long-Term Runoff Prediction Based on Deep Learning at Different Time Scales in the Upper Yangtze River Basin" Water 14, no. 11: 1692. https://doi.org/10.3390/w14111692