1. Introduction
High Mountain Asia (HMA) is the major water source of large river systems, especially of the Yangtze, the Yellow, the Brahamputra, the Ganges and the Indus river. It forms the freshwater supply for billions of people in Asia who depend on it as a drinking and agriculture water supply or source for hydropower electricity, and it is among the most vulnerable water towers globally [
1,
2]. Hence, it is becoming increasingly important to monitor and model water availability as the climate is changing. The three main direct sources of water in HMA rivers are direct precipitation, snow melt and glacier runoff, all of which experience drastic changes due to increasing temperatures and altered precipitation patterns [
3,
4,
5,
6].
Observing precipitation constitutes a challenge, especially in complex terrain with harsh climatic conditions and limited access [
7]. Precipitation measured with rain-gauge stations can provide information about spatial and temporal patterns, and they are therefore essential for monitoring and modeling. Direct observations at rain-gauge stations are (i) only available as point measurements; (ii) sparsely and unevenly distributed in space, especially in remote areas such as HMA; (iii) error-prone, especially for solid precipitation; and (iv) often discontinuous in time [
8,
9,
10,
11,
12,
13,
14]. Further limitations arise when comparing different gauge stations among each other due to different instrumentation and site characteristics. A heated tipping bucket will give different results than a non-heated bucket, and vegetation types and changes over time can influence measured precipitation and possible interpretations about what has caused these changes [
15].
To inform various research applications, such as hydrological models, precipitation data need to be continuous in both space and time. For this purpose, weather model-derived reanalysis datasets may provide spatially homogeneous gridded data. Gridded precipitation data can also be derived from interpolation of ground observations, which are subject to considerable uncertainties in data-scarce areas such as HMA [
16]. Retrieving precipitation from satellites is another method for generating gridded data. Precipitation measurement missions such as the Tropical Rainfall Measuring Mission (TRMM) [
17] and the Global Precipitation Measurement Mission (GPM) [
18] were established to continuously observe precipitation from space.
The choice of dataset to use for hydrological modeling applications greatly impacts the results, as there are significant differences between both absolute and relative values among datasets [
4,
7,
19,
20,
21,
22]. It is an inherent feature of the research problem that it is not possible to ultimately determine whether any of the datasets provides the “true” value of precipitation. Nevertheless, it is possible to make an informed decision about the choice of dataset by knowing about the differences, limitations and similarities, and through validation against ground truth data. Depending on the study area, some datasets may outperform others.
A major issue with gridded precipitation in rugged terrain, such as HMA, is the accurate representation of a grid-mean value that represents the local variability of precipitation. The terrain heterogeneity and topographical features get smoothed out in coarse-grid resolution products. It has been shown that the comparison between observed and modeled elevation within a global climate model leads to a bias of up to 2 km in elevation over HMA with higher inaccuracies on the edges of the Tibetan Plateau, which shows the highest gradients in topography [
23]. Besides the effect of altitude as such on the amount of precipitation, it can cause inaccuracies in spatial rainfall estimates due to local-scale dynamics of convective precipitation resulting from thermal slope breeze systems or orographically-induced precipitation.
The comparison of gridded data to actual measurements is problematic. Even though they are used in the majority of studies (e.g., [
4,
21,
22]), ground observation stations are also not fully representative of the areas of the grid cells in which they are located. Usually, gauge stations are located in valley bottoms rather than on top of the mountains or on slopes. Further error sources of gauge station data are the undercatch due to wind drift, especially during snowfall, wetting and measurement inconsistencies [
8,
13,
15,
24]. However, as surface measurements are the only ground truth observations of precipitation, they are also used as a reference in this study.
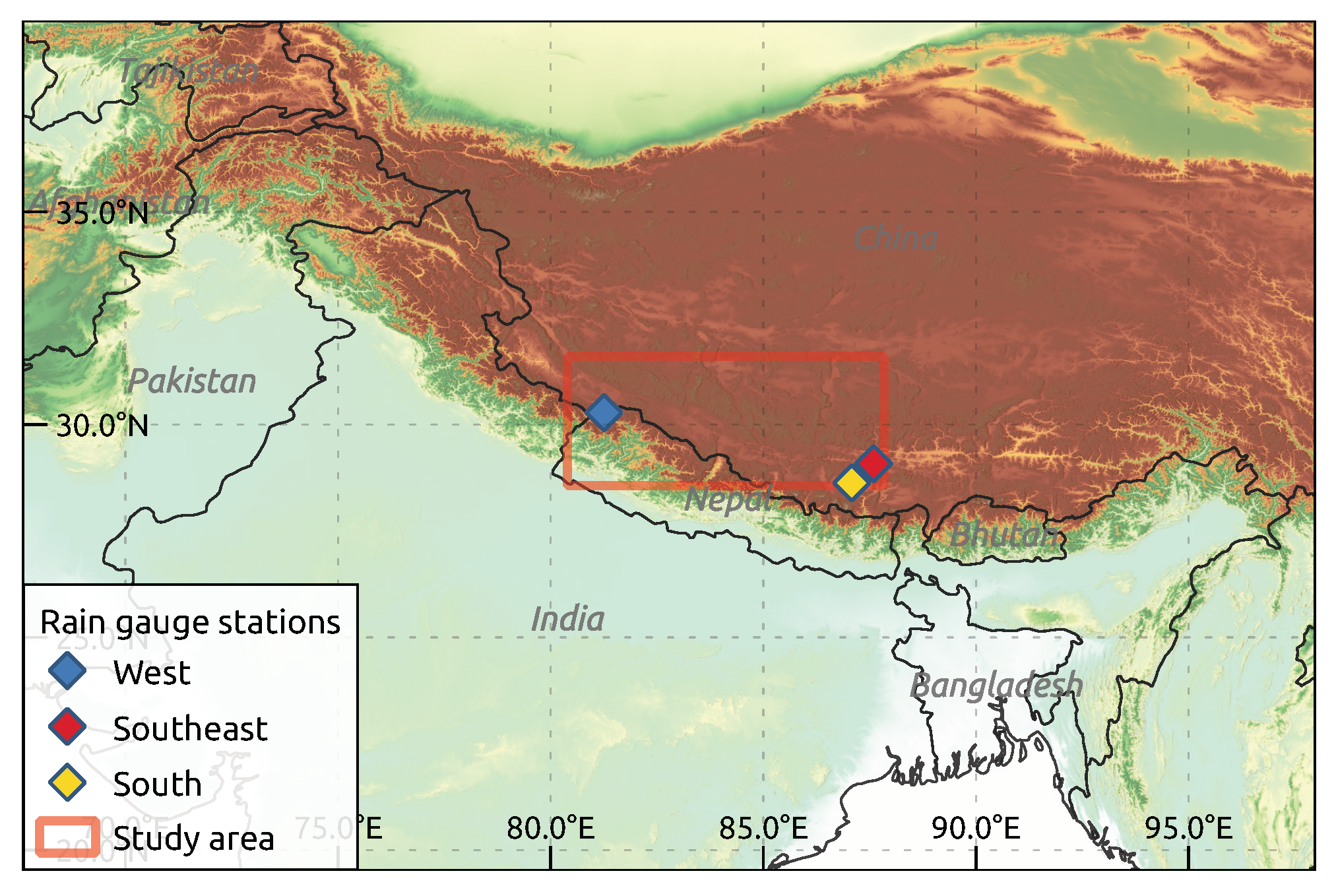
The scope of this study is to compare the global reanalysis datasets ERA5 [
25], ERA5-Land and ERA-Interim [
25,
26], the Japanese 55-year Reanalysis (JRA-55) [
27] and the Modern-Era Retrospective analysis for Research and Applications, Version 2 (MERRA-2) [
28], the regional WRF-downscaled High Asia Refined analysis version 2–10 km domain (HAR v2 10 km) [
29] and High Asia Refined analysis version 2–2 km domain (HAR v2 2 km) [
29] gridded products, the station based precipitation dataset Global Precipitation Climatology Centre (GPCC) and the satellite derived precipitation product Precipitation REtrieval covering the TIbetan Plateau (PRETIP) [
30,
31]. Further information on spatial and temporal resolutions of the datasets and websites for data downloads are shown in
Table 1. In a case study, we compared these datasets over a data-scarce sub-region covering each parts of the Tibetan Plateau (TiP), the Himalaya and the Himalaya foothills to the south during May to September 2017. To achieve a comprehensive intercomparison, we combined and extended different commonly used methods to inter-compare precipitation datasets and quantify differences based on terrain complexity. We finally compared gridded to rain-gauge data from the Chinese Ministry of Water Resources.
Comparable, longer-term comparisons across HMA have been carried out by e.g., Li et al., [
20], who found that grid resolution plays a significant role in overall mean precipitation and local maximum precipitation, that observation-derived datasets are likely to underestimate precipitation due to their locations in the valley bottoms and that satellite products show high uncertainties, especially for solid precipitation. Similarly, Gao et al. [
4] used precipitation indices to compare ERA-Interim reanalysis with WRF-downscaled products based on ERA-Interim and the community climate system model (CCSM) for the historical period and future projections over the Tibetan Plateau. They found that both ERA-Interim and CCSM greatly overestimate mean and extreme precipitation indices when compared to observation data. The dynamically downscaled products generally outperform their forcings in terms of absolute precipitation accuracy, and spatial and temporal patterns, indicating the importance of resolving small-scale processes. Similar conclusions were drawn by Huang and Gao [
19], stating that ERA-Interim and final analysis data from the Global Forecasting System (GFS-FNL) datasets largely overestimate precipitation over the Tibetan Plateau (TiP). This wet bias is reduced in WRF-downscaled products. Further work by Yoon et al. [
21] studied the terrestrial water budget over HMA, comparing different gridded precipitation data as boundary conditions for land surface models, including the older HAR (High Asia Refined analysis) version [
32]. Mean estimates of precipitation were found to differ significantly between products, while the spatial patterns and seasonality were reasonably captured in all products. The first HAR version has also been evaluated by Pritchard et al. [
33], who found that it is capable of representing precipitation in the Upper Indus Basin at multiple scales and matches ground observation data well. Furthermore, Wang and Zeng [
7] used several predecessors of the current study over the TiP and found that the Global Land Data Assimilation Systems (GLADS) data has the overall best performance for precipitation when compared to station data over the 1992–2004 period. GLDAS is derived as a combination from surface observations and remote sensing. Additionally, Bai et al. [
22] investigated different precipitation datasets over the Qinghai-Tibet Plateau, highlighting the importance of precipitation data in data-scarce regions and complex terrain such as the TiP. In their study satellite products, blended satellite and gauge station measurements, and climate modeling data, such as the HAR dataset, have been compared. They conclude that extreme precipitation is generally overestimated, while light precipitation (less than 1 mm day
−1) was mostly underestimated by most products.
In our study, we complement those earlier studies by including the new and even higher spatially resolved HAR v2 10 km and HAR v2 2 km datasets, and by applying additional ways of comparing different gridded precipitation datasets. We emphasize that differences between datasets must be discussed based on season, precipitation type and spatial context. With a set of selected analysis methods, our aim was to address the following key research questions: (1) How similar are the various gridded precipitation datasets? (2) What is the effect of terrain complexity on variations in precipitation between products?
4. Discussion
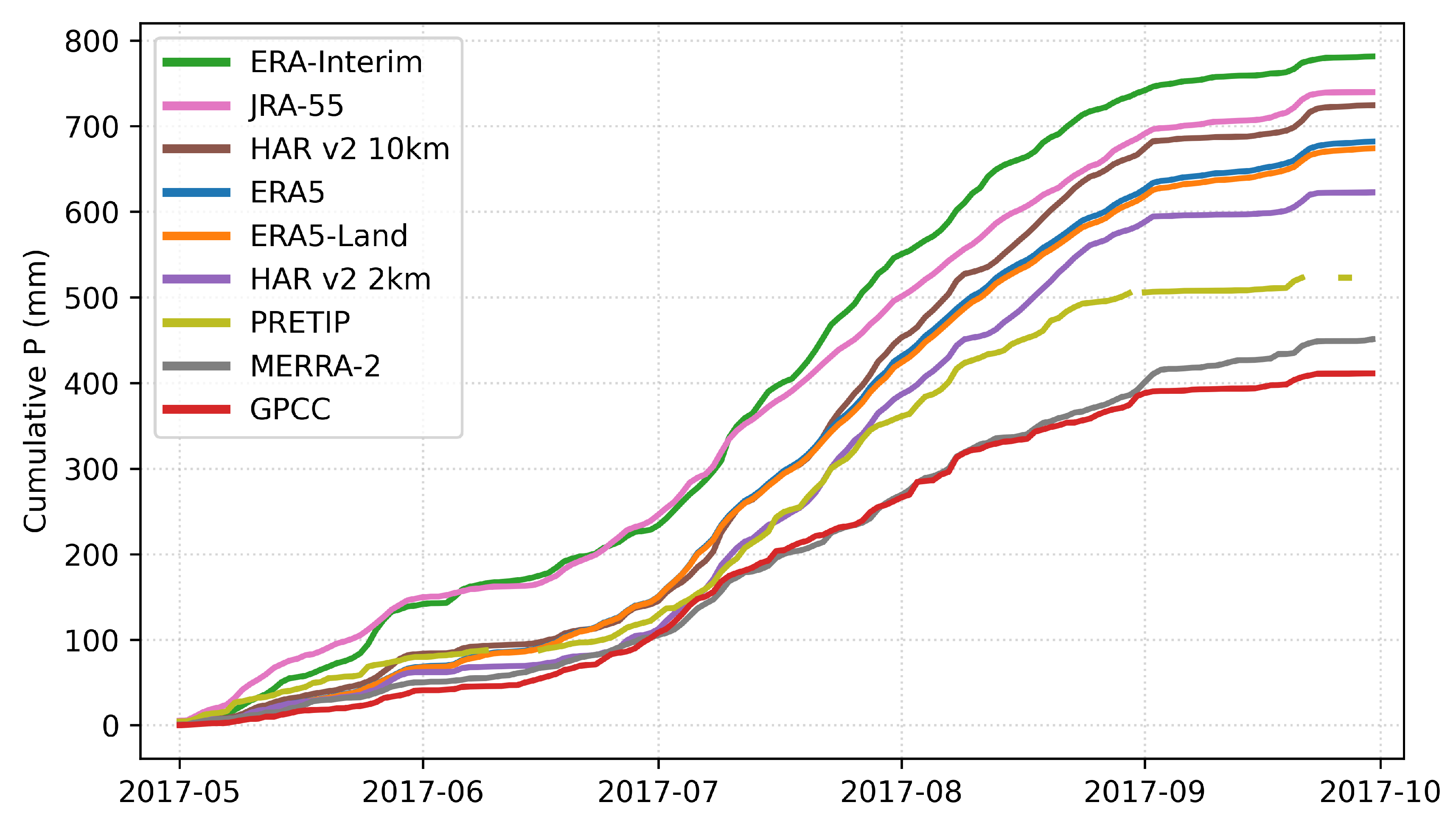
Despite the short period of analysis presented, it is possible to discover substantial similarities and differences between the different gridded precipitation products over the study area. As observed in
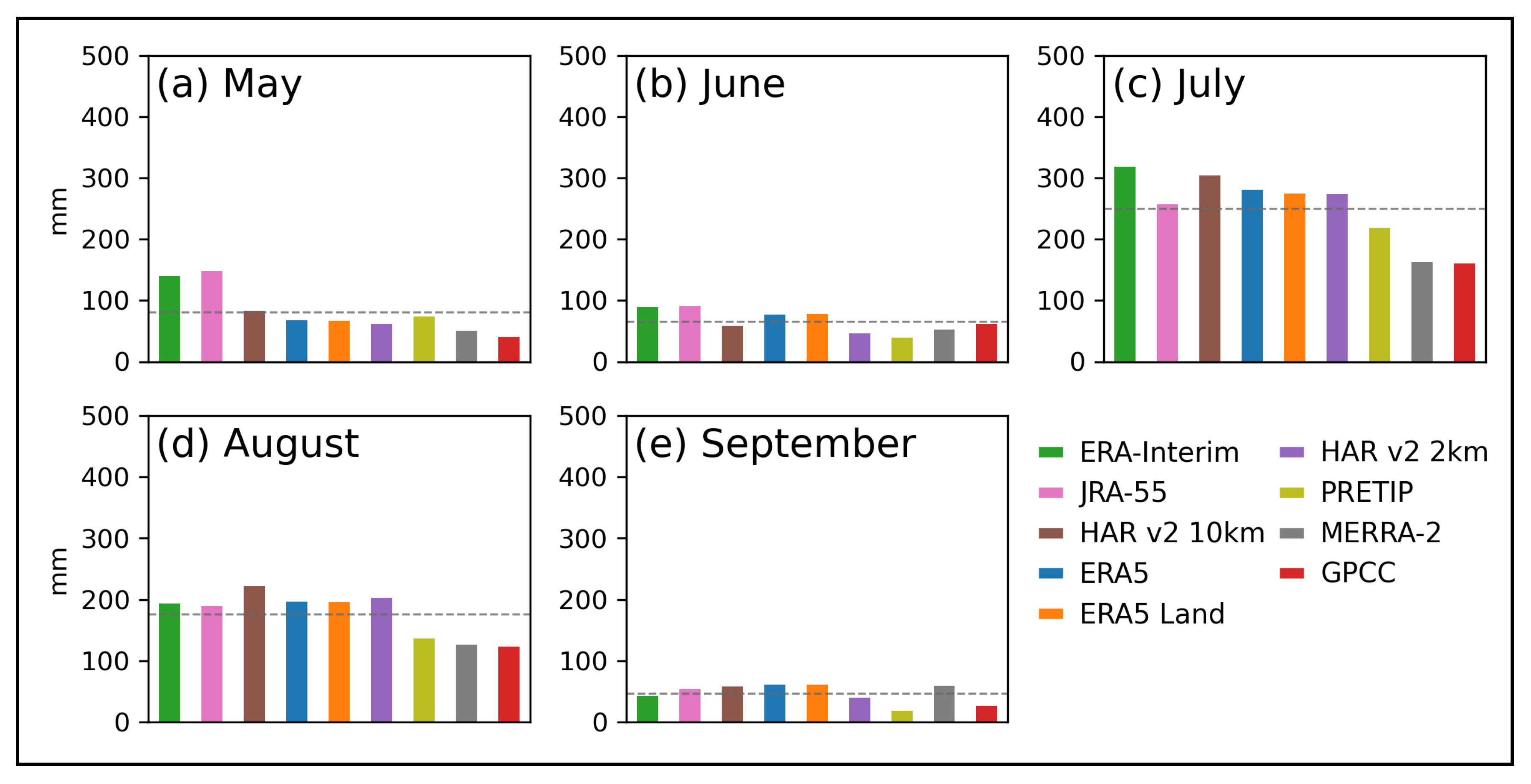
Figure 3, the study area is influenced by the Indian Summer Monsoon which becomes visible in the increase of precipitation during July and August and its withdrawal starting in September. Most products show a good agreement within the monsoon season, except for PRETIP, GPCC and MERRA-2. In addition, the area is also affected by the westerlies, which becomes visible in the pre-monsoon season (May). The inconsistency between JRA-55 and ERA-Interim and all other datasets might originate from different parameterizations for westerly-driven mostly solid precipitation. Combined, it appears that ERA5, ERA5-Land, HAR v2 10 km, HAR v2 2 km and for the most part PRETIP consistently match both the pre-monsoon and monsoon precipitation, while the remaining datasets have limitations in either one of those two periods.
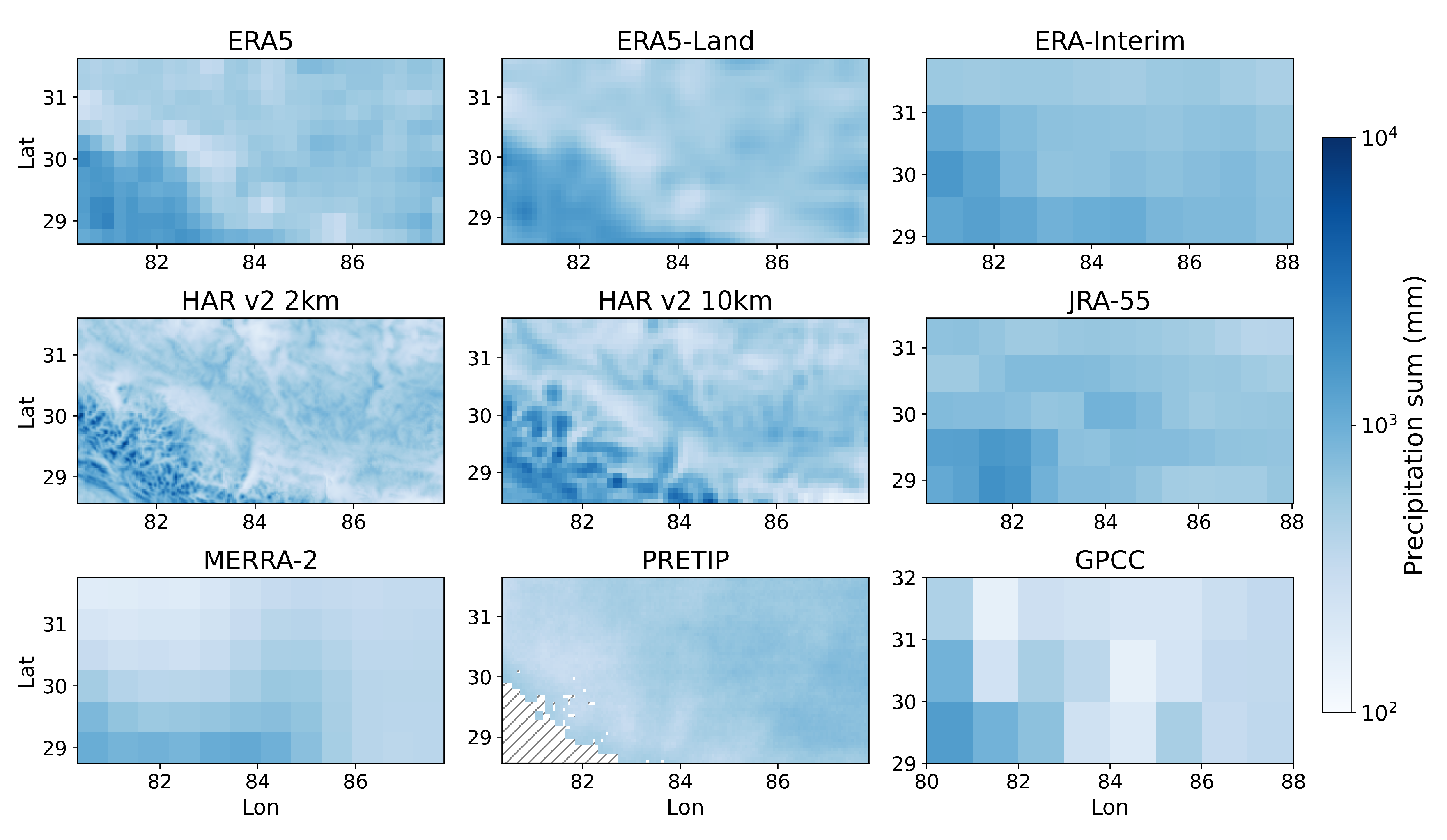
Based on the correlation between datasets, it became obvious that some are more similar than others. ERA5-Land and ERA5 are essentially identical when aggregating ERA5-Land to ERA5 resolution. This is to be expected, as ERA5 is using ERA5 atmospheric forcing to derive land-surface parameters. Hence, it should be noted that ERA5-Land does not add any value regarding orographically-induced precipitation over ERA5 when using atmospheric data. While all the ERA products and the ERA5-derived HAR products generally are very similar, the satellite product PRETIP exhibits the lowest correlations, even after aggregating precipitation over multiple days. Considering the spatial patterns of PRETIP precipitation, it is no surprise that the correlations are low. While the other products show a spatially decreasing trend in precipitation from southwest to northeast with a highly variable region in the Himalaya mountain range, PRETIP exhibits a much more homogeneous distribution throughout the study area. It even shows lower values for the Himalaya mountain range than the area covering the TiP. This is a result of the averaging character of the random forest algorithm which is smoothing for more extreme (low and high) precipitation and tends toward average precipitation rates. In future developments, the training should be either separated for convective and stratiform precipitation, or another machine learning algorithm that better captures meteorological extremes should be developed [
48,
49]. On the other hand, the similarities between the ERA products, the HAR products and to some extent JRA-55 lead to the conclusion that these products display the most likely range of precipitation in this study. The differences between those modeled datasets can be attributed to differences in model dynamics. This is in line with Zhang and Li [
50], who found that differences in moisture advection parameterizations greatly change precipitation patterns on steep slopes. It is not possible to ultimately say how well these products match the “true” precipitation. However, the few observations that are available suggest that the above mentioned products are the ones with precipitation amounts being the closest to actual precipitation amounts.
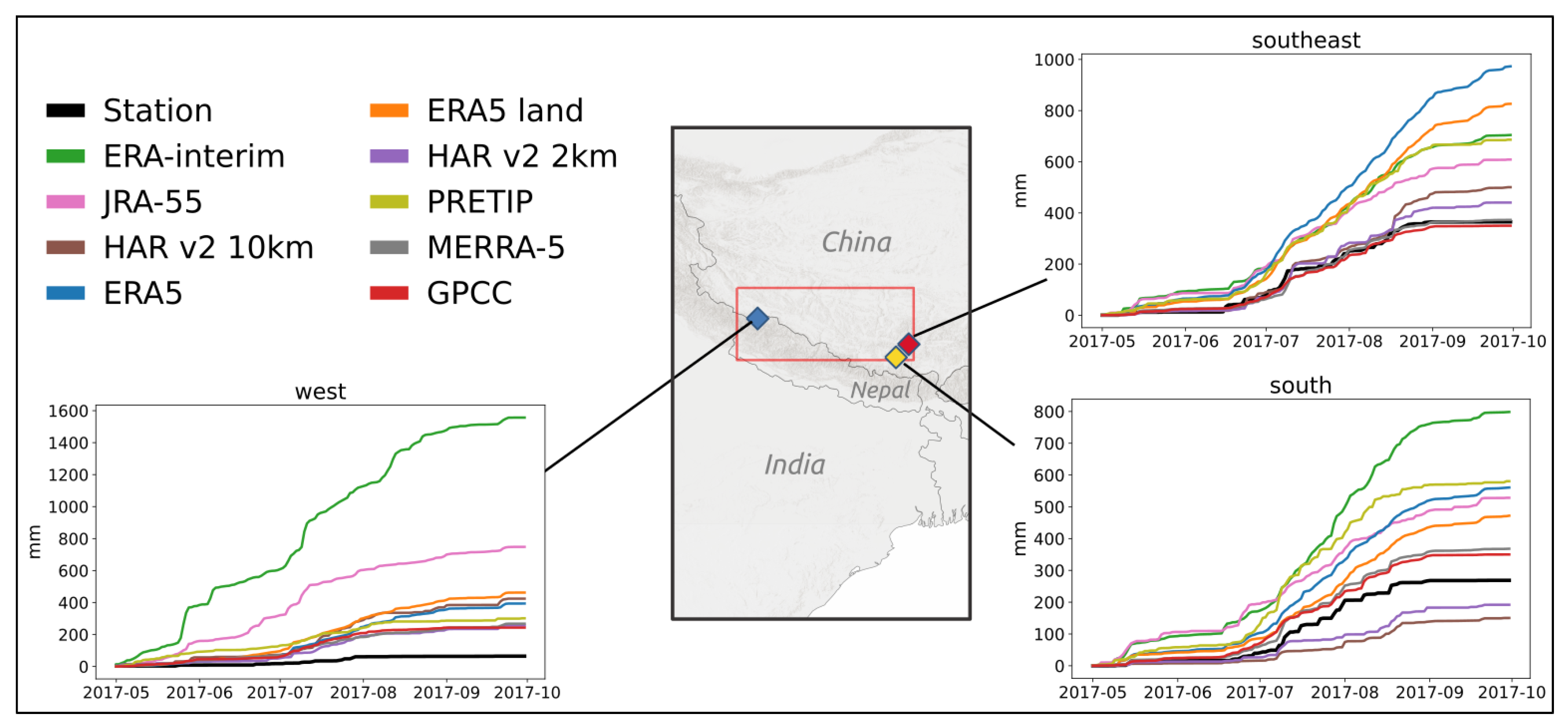
The comparison with rain gauge station data revealed that both HAR v2 datasets have the best matches with the ground observations. For the south and southeast stations, they also show very similar values, though they are more different at the west station. Here, the gauge station is located in a very localized, dry area, making local processes even more important. While these processes seem to be better represented in HAR v2 2 km, the 10 km grid seems to catch precipitation that might be outside the confined dry area. Considering ERA-Interim in this comparison, it becomes obvious that the extremely coarse grid resolution must be covering areas with higher precipitation outside the dry valley the station is located in. The elevation comparison between modeled elevation of ERA-Interim and the DEM-extracted elevation of the rain gauge station (
Table 2) shows that the station is located higher (4134 m a.s.l) than the modeled elevation of the ERA-Interim grid cell (3573 m a.s.l.). However, even though it is to be expected that stations located in low-lying areas would exhibit less precipitation than higher-lying areas, ERA-Interim shows much higher values than the gauge station, which emphasizes the limitations of trying to explain precipitation discrepancies by solely considering altitude as the determining factor. The good match between GPCC and the ground observations can be attributed to the fact that GPCC synthesizes station-based data and interpolates between them. Hence, it is to be expected that GPCC scores high correlations with surface observations in grid cells with observations, making it useful for individual grid-cells. However, the heavily interpolated values in between distant station data are subject to extreme uncertainties as no topograhical and regional features can be captured. Generally, rain gauge stations are often located in valley bottoms and easily accessible areas. Precipitation at the adjacent mountain peak or on its slopes might be higher, which can be represented by the modeled data, but not by rain-gauge station observations.
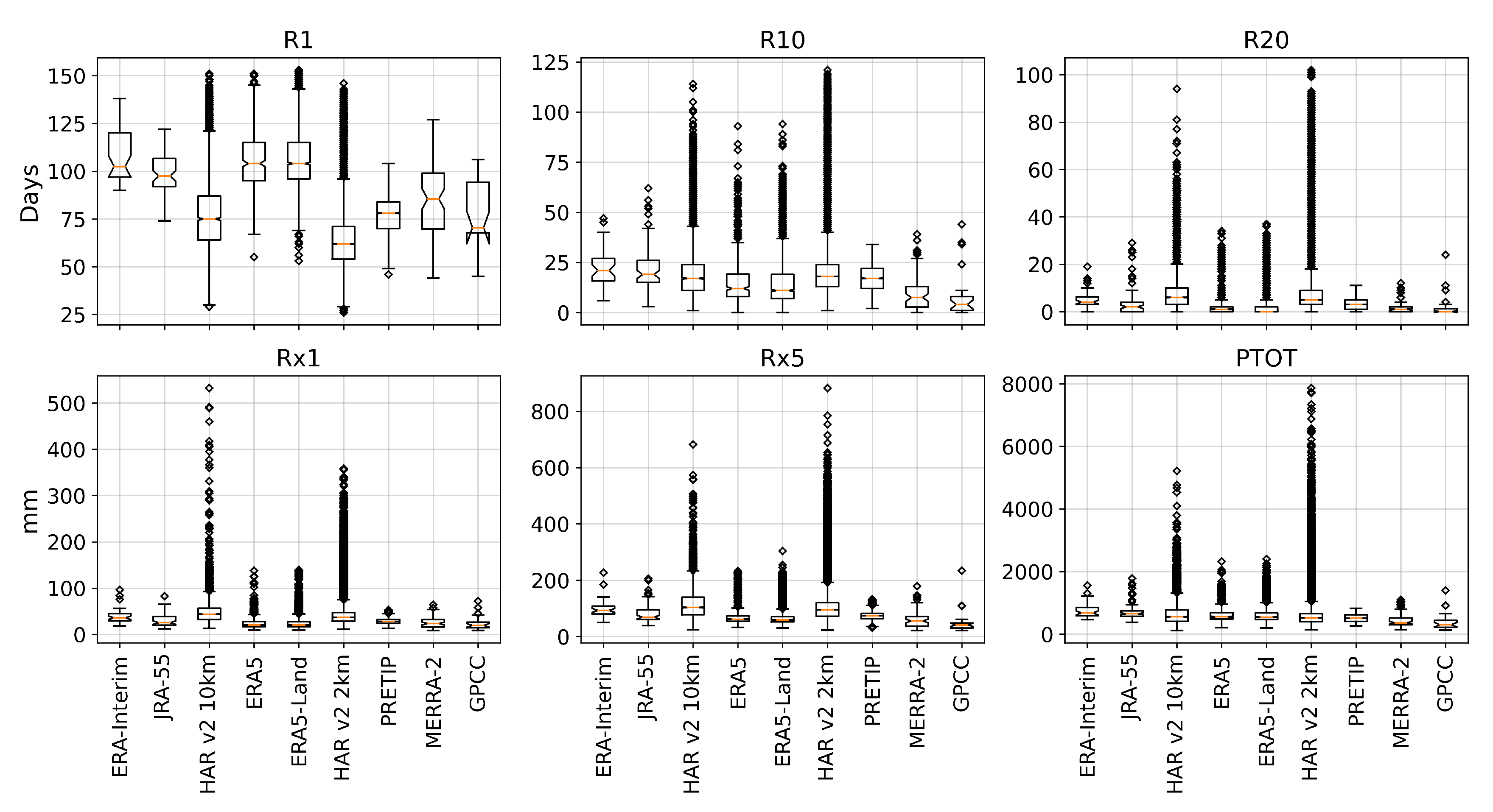
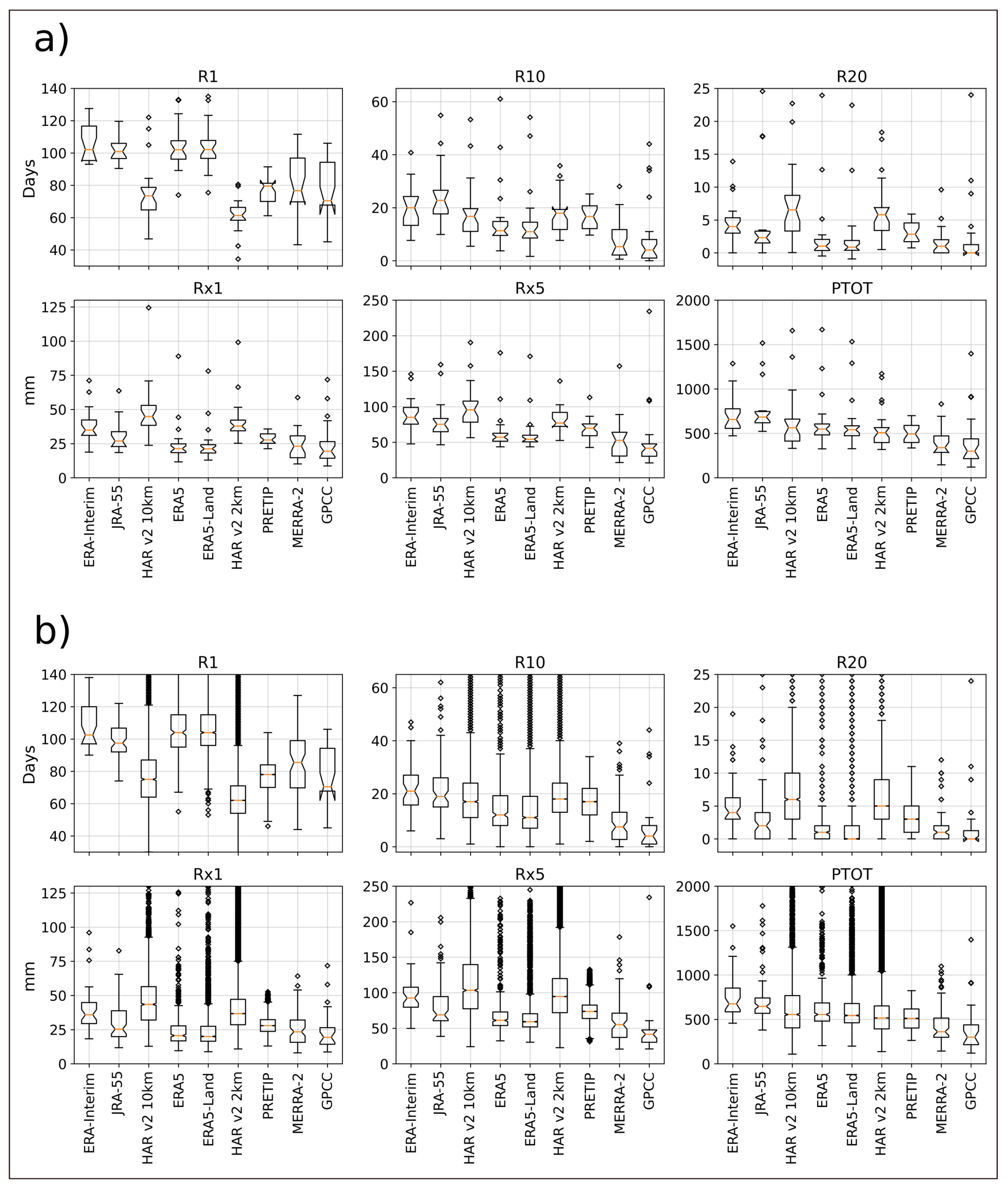
With the six climate indices (climdex) we found that the products with the highest grid resolution exhibited the highest number of days with heavy precipitation (R10 and R20) and the largest amount of precipitation in a single day and five consecutive days (Rx1 and Rx5). On the other hand, the mean values of the wet-day count (R1) were much smaller, which is an improvement compared to ERA-Interim precipitation in particular. According to Gao et al. [
4], ERA-Interim tends to overestimate precipitation on average, especially in the frequency of precipitation events. With the mean values of R1 in both HAR datasets in our case study being much lower than those in ERA-Interim, they seem to better represent the distribution of precipitation. The same feature, albeit lower in magnitude, can be observed between ERA-Interim and ERA5, indicating an improvement of precipitation representation between the two generations of ECMWF-reanalysis products in this specific case study. Overall, extreme precipitation events can occur in multiple grid cells within the higher-resolved HAR datasets. However, the cumulus parameterization in HAR v2 10 km seems to produce extremely high values of more than 500 mm in a single day, which does not happen in the 2 km grid version of the product. This finding is in accordance with Ou et al. [
51], in which high-resolution WRF experiments with and without cumulus convection scheme were conducted at a gray-zone grid spacing of 9 km. They found that the experiment without a cumulus scheme generally outperforms the experiments with cumulus schemes in terms of the mean total precipitation, and the diurnal cycles of precipitation amount and frequency. The total precipitation (PTOT) for all products shows that the maximum amount of a single grid cell can vary between less than 2000 mm up to almost 8000 mm. It became obvious that this cumulative difference in precipitation over only five months will strongly impact on the results of research applications if either one or the other product is chosen for the specific location.
Overall, our findings in terms of spatial resolution are in line with other studies, suggesting that higher grid resolution is needed to accurately represent terrain-induced precipitation patterns [
20]. In this study, only the HAR datasets and partly the ERA5 datasets were able to represent large orographic complexity. However, an increase in spatial resolution does not always yield higher accuracy in complex terrain, as can be seen within the PRETIP product, which is much more homogeneous than some of the lower resolved products. On the other hand, the coarsest product GPCC might perform much better in areas where individual grid cells contain measurements, while the interpolated cells in between are subject to high uncertainties. Further, GPCC has a high probability of underestimating precipitation due to the locations of ground observation stations being in valleys rather than on slopes or mountain summit areas.
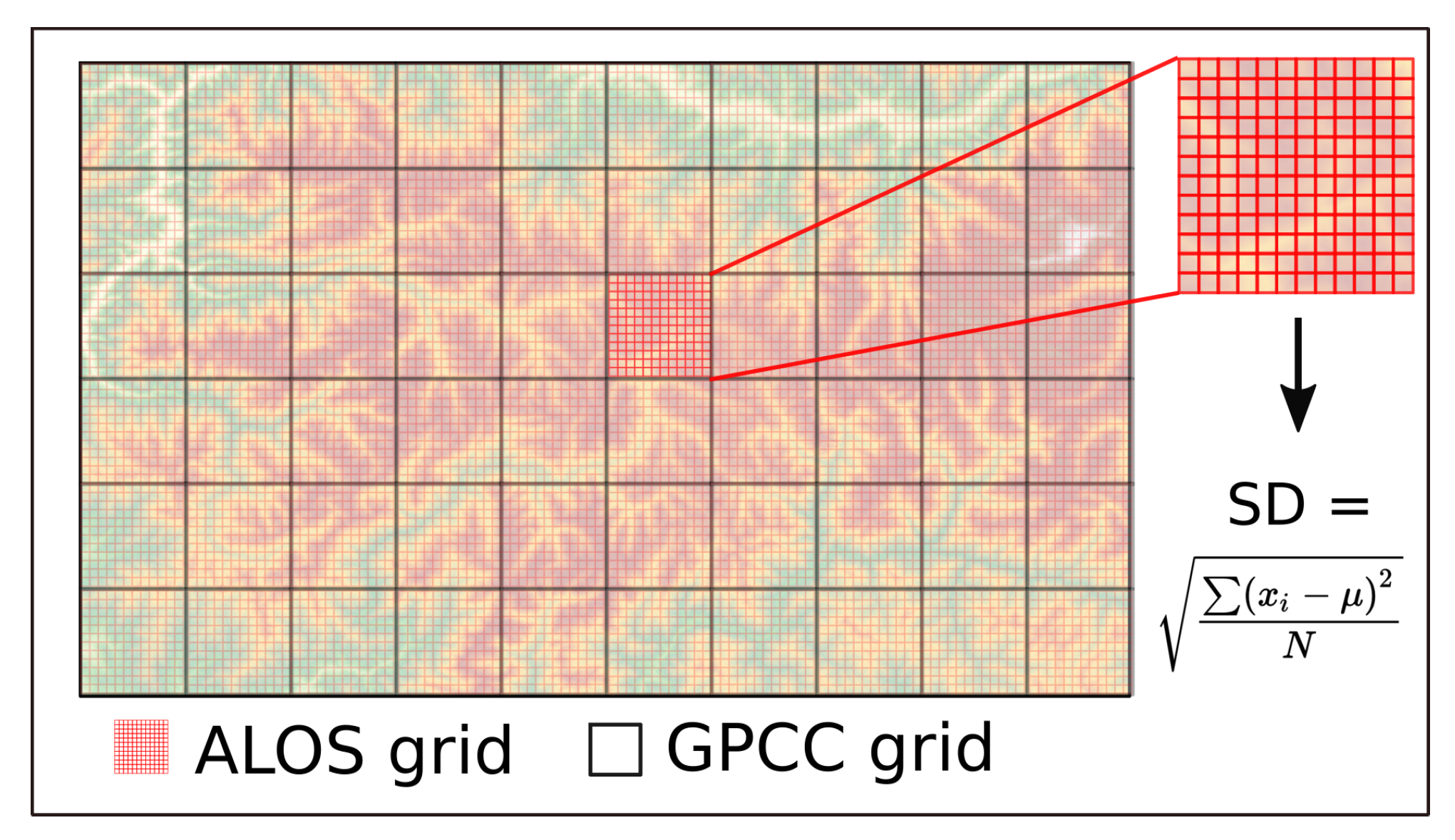
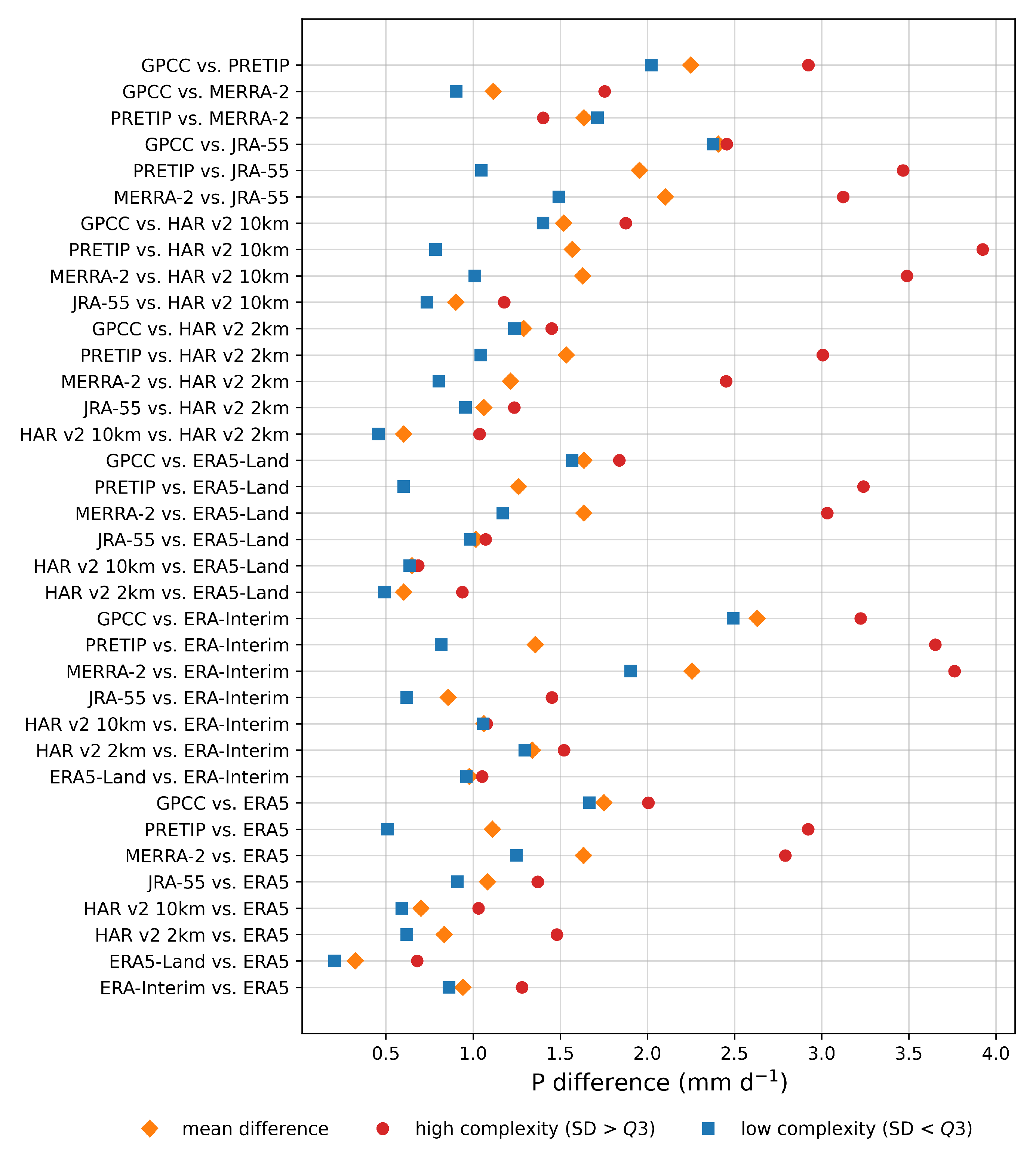
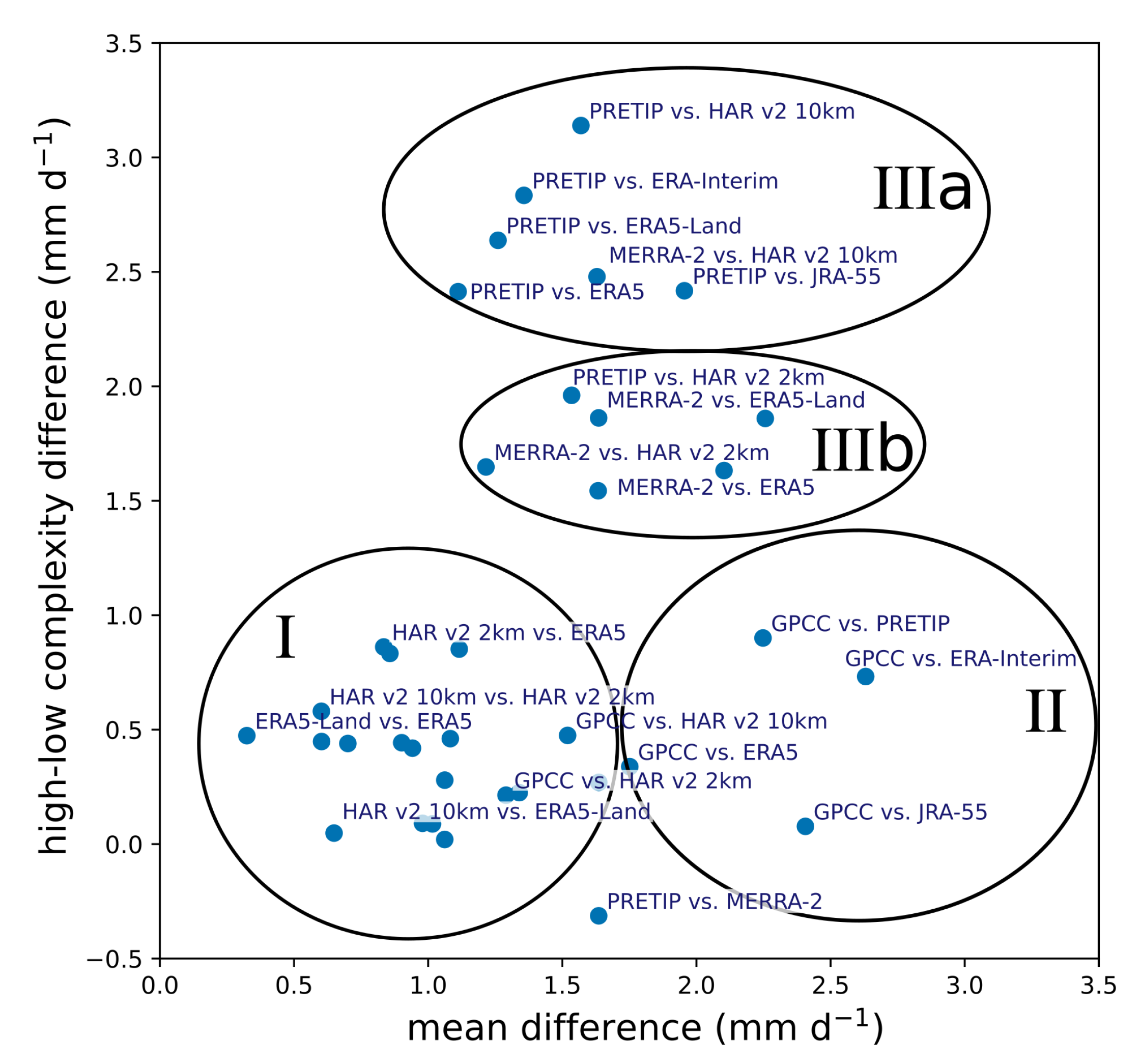
The role of terrain complexity was assessed with the help of a digital elevation model. We found that all datasets displayed higher differences in precipitation when the terrain complexity (ALOS standard deviation) was larger than Q3, except for one pair (PRETIP and MERRA-2). Based on the grouping of the pairs depending on their relationship between mean difference and precipitation, for the difference between high and low complexity terrain four main clusters can be derived (
Figure 9). While cluster I includes most of the similar datasets, such as ERA and HAR datasets due to their overall similarity, cluster II comprises mostly comparisons with the coarsely resolved GPCC product. The greater overall mean difference between GPCC and the other products is most likely a result of the heavily interpolated values for grid cells without measurements. However, terrain complexity does not seem to have a significant additional impact on the differences. Cluster IIIa and IIIb are mostly dominated by comparisons with PRETIP and MERRA-2. While the differences with PRETIP are attributable to the averaging nature of the random forest approach and the resulting smoothing in complex terrain, the comparisons with MERRA-2 canot be interpreted in a straight forward way. All comparisons with MERRA-2, except for the comparison between PRETIP and MERRA-2, are grouped within cluster III, which leads to the conclusion that precipitation in terrain with high complexity within MERRA-2 seems to be weaker compared to most other products. The inverse behavior of the pair PRETIP and MERRA-2 in terms of precipitation in complex terrain vs. less complex terrain is probably attributable to the fact that this pair has the lowest overall correlation for daily values and hence has the largest differences in all grid cells, independently of topography.
5. Conclusions
This study presents the intercomparison of nine differently generated gridded precipitation products from a study area in HMA from May to September 2017. Precipitation as boundary condition for any research application can greatly influence the outcome and respective interpretation. In order to be able to understand and predict the future behavior of a system, it is necessary to apply tools, such as modeling, which require a certain spatial and temporal coverage of their input data. This is particularly challenging for remote regions with complex terrain, such as in HMA. Making an informed decision about the boundary conditions used for the respective applications is key to achieving reliable predictions and can be a difficult endeavor. In this study, we highlighted the similarities and differences of spatially and temporally continuous gridded precipitation data from various sources over one full monsoon period that can be used as boundary conditions for longer-term applications, such as climate-change assessments, runoff-calculations, glacier mass balance modeling and hydropower-applications, among others. While a product with coarse grid resolution such as ERA-Interim might be able to reproduce seasonal patterns and long-term climate trends [
4], glacier modeling applications might require much higher grid resolution as for example in HAR v2 2 km, which resolves processes related to local topography much better than products based on coarser grids. However, the HAR v2 2 km product has high computational demands due to its high resolution dynamical downscaling. It is only available for distinctive study regions and periods where it is of high value to analyze the effects of grid resolution and topography. The HAR v2 10 km, on the other hand, shows very good matches with observational data and is available for a longer periods and the entire HMA. It shows slight limitations compared to the 2 km version originating from the cumulus parameterization, which can overestimate precipitation falling in a single day. Nonetheless, HAR v2 10 km is the only product (together with HAR v2 2 km) that is able to resolve topographic precipitation features (c.f.
Figure 5). Similarly, gauge station data might not be representative of the wider areas due to their typical locations in areas of low-complexity terrain. Hence, products derived from station data such as GPCC might underestimate areal precipitation, especially if there are only one or two stations within a grid cell, as is usually the case in HMA. Higher grid resolution, as in PRETIP, on the other hand, might also not improve precipitation estimates, as this satellite-based product is limited to the averaging within the random-forest methodology. We therefore suggest to not only rely on a single dataset in any application but to elaborate on the potential influences of different datasets in comparison. We suggest selecting a precipitation dataset based on one’s application and requirements. For example, if data are needed for multi-decadal hydro-meteorological or hydro-climatological research applications, ERA5 is currently the best choice. When HAR v2 10 km becomes available for longer periods it will replace ERA5 in this position. If precipitation in complex terrain at high spatial resolution is to be investigated, HAR v2 2 km would be the optimally applicable dataset, which might still require bias correction for local applications. HAR v2 10 km and ERA5 might be employed over larger study areas or extended study periods. Similarly, glacio-hydrological studies, which usually expand over small areas, require high spatial resolution to accurately represent the prevailing accumulation patterns of the area. For studies focusing on the broader precipitation patterns under consideration of terrain complexity, most ERA products, the HAR products and JRA-55 have shown to be very similar. PRETIP offers a great opportunity for near-real time applications, such as flood forecasting, as the satellite data can be available within hours after the passage of the satellite, whereas reanalysis products are only available after several weeks.
Overall, in this study we elaborate and conclude on the following:
(1) How similar are the different gridded precipitation datasets? Depending on the origins and generation of the datasets, some datasets are very similar (e.g., HAR v2 2 km and HAR v2 10 km; ERA5 and ERA5-Land), while other datasets show larger discrepancies (e.g., Merra and GPCC). Despite some data gaps, the satellite product (PRETIP) falls within the range of cumulative precipitation and shows similar trends to other products. When comparing the grid values to station data, we conclude that spatial resolution plays a significant role and that gauge measurements likely exhibit a dry bias due to their locations on valley floors or other areas of low terrain complexity. However, most products represent the timing and patterns of precipitation events well.
(2) What is the effect of terrain complexity on variations in precipitation between products? Terrain complexity increases the difference of precipitation between products. In complex terrain, the difference within daily precipitation can be up to 4 mm d−1, whereas it is generally below 2 mm d−1 in more homogeneous landscapes. Overall, the differences in precipitation derived from the analysis based on terrain complexity enables one to draw conclusions on how well some products work for studies focusing on complex terrain. For instance, it is possible to use the ERA5-Land dataset rather than the HAR v2 10 km dataset, if the latter is not available. Locally, the differences can still be large, but the overall precipitation estimates over a wider area are consistent between both datasets.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










