
Abstract
Road traffic is associated with a variety of negative externalities such as air pollution and environmental noise, with significant short- and long-run health impacts on infants. This paper empirically quantifies the effects of traffic negative externalities on infant health, focusing especially on how they differ across income groups. We assemble a rich micro-dataset of infant birth outcomes, parental demographics, and neighborhood characteristics to specify and estimate a health model and an equilibrium sorting model. Our results demonstrate that traffic negative externalities reduce birth weights by over two times greater in the lowest-income than in the highest-income families. In addition, the effect of change in income from the poorest to the richest group lifts average birth weights by 0.56% among exposed families, while the income change has no impact on unexposed families. We also find that policies affecting traffic pollution exposure lead to residential sorting. The self-selection of the sorting process causes the lowest-income families to allocate away from neighborhoods experiencing policy-driven environmental improvement, negating the positive benefits of environmental policy. The magnitude of the sorting effect, however, is relatively small.




Similar content being viewed by others
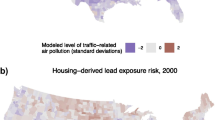

Notes
We removed subjects with birth weight below 300 g (0.03%) and above 6000 g (0.01%) as well as those with multiple births (3.49%) and missing or unknown values for mother age (0.003%), maternal complications (0.32%), and delivery weight (1.23%) and pregnancy weight (0.58%). Additionally, we include a category for missing data for each categorical variable. Finally, subjects with adjusted real-market housing values below $5,000 (2.26%) and above 99th percentile (0.96% of births) are also excluded (2014 is the base year when we adjust for the inflation).
Total property value is the total of building value and land value.
Note that the RMV is distinct from “assessed value”, which is used for the purpose of calculating property taxes. In Oregon, county assessors are required to estimate RMV for each parcel, which is comparable to the competitive market price at which a land parcel would be exchanged in an arms-length transaction. The advantage of using assessor estimates of RMV is that it is available for each parcel every year, which is not the case of sales price since housing transactions take place with a low frequency. We have adjusted the RMV for inflation using 2014 as the base year.
Census-block-group level median income data is only available for year 2000, 2013, and 2014 for the study area.
The year 2000 census boundaries shifted in 2010. These boundaries must be the same to ensure accurate results of the linear interpolation. Hence, we aggregate each variable as an area weighted sum from the block level to the circular neighborhood level. The number of elements in the weighted sum varies. Census blocks are small in population dense areas and big in less populated areas. Consequently, more blocks are aggregated into one circular neighborhood in densely populated areas than in remote rural areas.
We spatially join mothers/infants (point) to the closest circular neighborhoods (polygon). A distance field is calculated to the boundary of a polygon to show how close the polygon is. A polygon that the points fall inside is treated as being closest to the point (i.e. a distance of 0). When two or more points are at the same distance from the polygon, one of the polygons is randomly selected as the matching feature. The circular neighborhoods are tangent to the neighborhoods around them but they do not overlap with each other.
Since all the neighborhoods are circles with the same size, total population measures the population density.
Parks include all local and state parks, and natural areas that belong to cities, the state, and the federal government in the Portland Metropolitan area.
Continuous Pressure Sound Level (Leq) is a fundamental measurement parameter designed to represent a varying sound source over a given time as a single number.
Alternative cutoffs of 150 m. and 500 m. were used to perform sensitivity analysis and give us similar results.
Traffic volume is measured as the combined auto and truck modeled volume crossing the road. Trucks are considered as passenger car equivalents – 1 truck = 1.7 cars due to the extra capacity they occupy on the system.
The units are vehicles crossing the road during the afternoon peak two-hour period (4:00 pm–6:00 pm) in each year (2000, 2005, and 2010).
As a robustness check, we estimate the health model using logged exposure distance as pollution exposure measurement. The result is presented in Appendix Table 8. The coefficient of logged exposure distance is positive and strongly significant, showing birth weight increases when mother live further away from roads with heavy traffic.
We logged the dependent variable to capture birth weight outliers (i.e. extremely low and high birth weight).
This does not include the value of the land.
We tested 1% thresholds as a robustness check. Results are insensitive to the cutoff changes. As a reference, the poverty threshold in Oregon is 24,008 dollars with two parents and two children in 2014 (Oregon Center for Public Policy, 2015).
We join both single family housing and multi-family housing transactions with the Vital Statistics record and use both to estimate model (1).
Maternal illness and complications include breech birth, meconium passage, premature rupture, induction of labor, augmentation of labor, precipitous labor, prolonged labor, fetal intolerance, pregnancy/chronic diabetes, gestational diabetes, pregnancy hypertension, gestational hypertension, eclampsia hypertension, previous preterm birth, and uterine bleeding.
Note that linear interpolation of some neighborhood characteristics does not affect interpretation of year fixed effects. Interpolation means that, for some years, these characteristics change at a constant rate, which varies across neighborhoods. Year fixed effects, on the other hand, capture changes over time in unobservables that are the same for all neighborhoods, and because there is a dummy for every year these unobservables are allowed to vary at a non-constant rate over time.
While one might anticipate a negative correlation between exposure and propeorty values, in our data areas with high traffic-related pollution are also close to the city center and have high house values, likely due to presence of other amenities. Distance to city center is included as a controlled variable.
Father’s race, age, and education level are not matched because there are too many missing values.
These variables are mother age, marital status, mother’s education, mother’s race, maternal smoking, and real-market value of mother’s property.
The rule of thumb is that a standardized difference in means above 0.25 can cause bias in regression estimates (Imbens and Wooldridge 2009).
We tested 1, 2, 3, and 4 nearest neighbors with replacement and one-to-one exact matching with replacement; results are generally robust to matching algorithms and number of neighbors.
Radius matching was also used as a sensitivity test and gives similar results.
Common support condition (or overlap) ensures that 0 < P(D = 1|X) < 1. That is, observations with the same covariate values have a positive probability of being both exposed and unexposed.
The standardized difference is defined as the difference of sample means in the treated and control subgroups as a percentage of the square root of the average of sample variances in both groups: \(\frac{(\overline{{X }_{1}}-\overline{{X }_{0}})}{\sqrt{\frac{{V}_{1}\left(X\right)+{V}_{0}\left(X\right)}{2}}}\) (Caliendo and Kopeinig 2005).
We dropped 74,470 observations after matching. Every observation in the treatment (exposed) group is matched with observations in the control (unexposed) group. This is known as trimming the sample.
Since we use one-to-one nearest neighbor matching with replacement, individuals from the control group are used more than once as a match. Allowing replacement substantially decreases bias and leads to high matching quality. This, however, reduces the number of distinct observations (sample size), which leads to low p-values. Past literature indicates that using statistical significance testing to evaluate covariate balance is discouraged because it is sensitive to sample size (Austin, 2011; Imai, King, & Stuart, 2008). The statistical difference in means between the treatment and control groups does not affect the balance of our matched sample. According to Caliendo and Kopeinig (2008), if standardized bias is reduced to below 5% after matching, the matching method is considered effective in balancing the distributions of the covariate. As shown in Table 2, the standardized difference is mostly below 5% after matching with significant bias reduction, indicating that our matched sample is well balanced.
Following Klaiber and Phaneuf (2010), choice sets in the sorting model are constructed from three components – house location, house size, and transaction time. Neighborhoods where houses are located form the choice sets’ location component and are defined in the same manner as in the health model. The second component considered in choice set construction is house size. House size is divided into three categories – small, medium, and large. Tertiles are used to define house sizes. The lowest tertile (i.e. 0%-33%) corresponds to small houses; the second tertile (i.e. 33%-66%) defines medium houses; the highest tertile (i.e. 67–100%) contains large houses. The final component of the choice sets is the time of the housing transaction. To match time period with traffic volume data, we define three aggregate time periods for the 15 years of the study period: 2000–2004, 2005–2009, 2010–2014 corresponding to the traffic volume data available for 2000, 2005, and 2010. There are a total of 8,391 housing types. Transactions are assigned to a house type given its neighborhood, time, and house-size combinations. On average a house type contains approximately 48 housing transactions, providing substantial statistical variation. Aggregating houses into groups also reduces the number of choice alternatives, facilitating estimation. We therefore have three time equilibrium in each time period.
Due to computational difficulty, we did not allow housing prices to be heterogeneous across housing types. In other words, \({p}_{h}\) is not interacted with individual demographics \({d}_{r}^{i}\).
Given that single-house transactions are aggregated into housing types, housing characteristics and sales prices are medians for all housing transactions within a housing type.
A study has shown that traffic flow elasticity to gasoline price changes is -0.050 on highways without a high-occupancy vehicle (HOV) lane (Bento et al. 2012). In that way, a $1.84 gas tax would lead to a 5% traffic volume decline, given that the current Oregon average price of gasoline was $1.84 per gallon during 2000–2010 (EIA 2017).
Note that housing price in the sorting model is not transaction price for an individual house, but the median price of a housing type.
The percent impact of pollution exposure status change from 0 to 1 on birthweight is (exp(\({\alpha }_{1}-{\alpha }_{4}\)) \(-\) 1)*100% = (exp(−0.0127)−1)*100% = -1.27% in the lowest-income group. Similar calculation is done to compute the exposure effects among the mid- and higher-income families.
Again, since smoking is a binary variable, the relative effect of smoking is (exp(-0.0478)*100% = −4.67%
The coefficient of the mid-income group is not statistically significant. As a robustness check, we test different income group thresholds and whether the income effect is statistically different across the mid- and highest-income groups. While there is a very small difference between the income effects across the two income groups in our original specification (p-val = 0.073), the results disappear in other specifications and are not robust. Therefore, our conclusion that there is heterogeneity in the income effect on birth weight, and the income effect goes away for income levels beyond that of the lowest-income groups still holds.
This is the aggregated average of birth weight percentage change among individuals in all three income groups and are no longer exposed at the post sorting stage.
References
Argys L, Averett S, Yang M (2019) Residential noise exposure and health: evidence from aviation noise and birth outcomes. https://www.iza.org/publications/dp/12605/residential-noise-exposure-and-health-evidence-from-aviation-noise-and-birth-outcomes
Banzhaf HS, Walsh RP (2008) Do people vote with their feet? An empirical test of Tiebout. Am Econ Rev 98(3):843–863. https://doi.org/10.1257/aer.98.3.843
Basner M, Babisch W, Davis A, Brink M, Clark C, Janssen S, Stansfeld S (2014) Auditory and non-auditory effects of noise on health. The Lancet 383(9925):1325–1332. https://doi.org/10.1016/S0140-6736(13)61613-X
Bates LK (2013) Gentrification and displacement study: implementing an equitable inclusive development strategy in the context of gentrification. https://works.bepress.com/lisa_bates/2/
Bayer P, Ferreira F, McMillan R (2007) A unified framework for measuring preferences for schools and neighborhoods. Working Paper No. 13236. National Bureau of Economic Research. https://doi.org/10.3386/w13236
Bayer P, McMillan R, Rueben K (2004) An equilibrium model of sorting in an urban housing market. Working Paper No. 10865. National Bureau of Economic Research. http://www.nber.org/papers/w10865
Bayer P, Timmins C (2007) Estimating equilibrium models of sorting across locations. Econ J 117(518):353–374
Bento AM, Hughes JE, Kaffine D (2012) Carpooling and driver responses to fuel price changes: evidence from traffic flows in Los Angeles (SSRN Scholarly Paper ID 2135650). Social Science Research Network. https://papers.ssrn.com/abstract=2135650
Berry S, Linton OB, Pakes A (2004) Limit theorems for estimating the parameters of differentiated product demand systems. Rev Econ Stud 71(3):613–654
Berry S (1994) Estimating discrete-choice models of product differentiation. RAND J Econ 25(2):242–262
Berry S, Levinsohn J, Pakes A (1995) Automobile prices in market equilibrium. Econometrica 63(4):841–890
Buka I, Koranteng S, Osornio-Vargas AR (2006) The effects of air pollution on the health of children. Paediatr Child Health 11(8):513–516
Caliendo M, Kopeinig S (2005) Some practical guidance for the implementation of propensity score matching. Iza Discussion Paper, 1588
Case A, Lubotsky D, Paxson C (2001) Economic status and health in childhood: the origins of the gradient. Working Paper No. 8344. National Bureau of Economic Research. https://doi.org/10.3386/w8344
Chay K, Greenstone M (2003a) The impact of air pollution on infant mortality: evidence from geographic variation in pollution shocks induced by a recession. Q J Econ 118(3):1121–1167. https://doi.org/10.1162/00335530360698513
Chay K, Greenstone M (2003b) Air Quality, Infant Mortality, and the Clean Air Act of 1970 (NBER Working Paper No. 10053). National Bureau of Economic Research, Inc. http://econpapers.repec.org/paper/nbrnberwo/10053.htm
Chay KY, Greenstone M (1998) Does air quality matter? Evidence from the housing market (Working Paper No. 6826; Working Paper Series). National Bureau of Economic Research. https://doi.org/10.3386/w6826
Conefrey T, Gerald JDF, Valeri LM, Tol RSJ (2013) The impact of a carbon tax on economic growth and carbon dioxide emissions in Ireland. J Environ Planning Manage 56(7):934–952. https://doi.org/10.1080/09640568.2012.709467
Conley D, Bennett NG (2001) Birth weight and income: Interactions across generations. J Health Soc Behav 42(4):450–465
Conley D, Bennett NG (2000) Is biology destiny? Birth weight and life chances. Am Sociol Rev 65(3):458–467. https://doi.org/10.2307/2657467
Currie J (2011) Inequality at birth: some causes and consequences. Am Econ Rev 101(3):1–22. https://doi.org/10.1257/aer.101.3.1
Currie J (2013) Pollution and Infant Health. Child Dev Perspect 7(4):237–242. https://doi.org/10.1111/cdep.12047
Currie J, Davis L, Greenstone M, Walker R (2015) Environmental health risks and housing values: evidence from 1,600 toxic plant openings and closings. Am Econ Rev 105(2):678–709. https://doi.org/10.1257/aer.20121656
Currie J, Moretti E (2007) Biology as destiny? Short- and long-run determinants of intergenerational transmission of birth weight. J Law Econ 25:231–264
Currie J, Neidell M (2005) Air pollution and infant health: what can we learn from California’s recent experience? Q J Econ 120(3):1003–1030
Currie J, Neidell M, Schmieder JF (2009) Air pollution and infant health: lessons from New Jersey. J Health Econ 28(3):688–703. https://doi.org/10.1016/j.jhealeco.2009.02.001
Currie J, Rossin-Slater M (2015) Early-life origins of life-cycle well-being: research and policy implications. J Policy Anal Manag 34(1):208–242
Currie J, Walker R (2011) Traffic congestion and infant health: evidence from E-ZPass. Am Econ J Appl Econ 3(1):65–90. https://doi.org/10.1257/app.3.1.65
Currie J, Zivin JG, Mullins J, Neidell M (2014) What do we know about short- and long-term effects of early-life exposure to pollution? Annu Rev Resour Econ 6(1):217–247. https://doi.org/10.1146/annurev-resource-100913-012610
Davis LW, Kilian L (2011) Estimating the effect of a gasoline tax on carbon emissions. J Appl Economet 26(7):1187–1214. https://doi.org/10.1002/jae.1156
DeCicca P, Malak N (2020) When good fences aren’t enough: the impact of neighboring air pollution on infant health. J Environ Econ Manag 102:102324. https://doi.org/10.1016/j.jeem.2020.102324
Dehejia RH, Wahba S (1998) Propensity score matching methods for non-experimental causal studies (Working Paper No. 6829). National Bureau of Economic Research. https://doi.org/10.3386/w6829
Ellickson B (1971) Jurisdictional fragmentation and residential choice. Am Econ Rev 61(2):334–339
Epple D, Platt GJ (1998) Equilibrium and local redistribution in an urban economy when households differ in both preferences and incomes. J Urban Econ 43(1):23–51
Epple D, Romer T (1991) Mobility and redistribution. J Polit Econ 99(4):828–858
Ferraro PJ, Miranda JJ (2014) The performance of non-experimental designs in the evaluation of environmental programs: a design-replication study using a large-scale randomized experiment as a benchmark. J Econ Behav Organ 107(Part A):344–365. https://doi.org/10.1016/j.jebo.2014.03.008
Ferraro PJ, Miranda JJ (2017) Panel data designs and estimators as substitutes for randomized controlled trials in the evaluation of public programs. J Assoc Environ Resour Econ 4(1):281–317. https://doi.org/10.1086/689868
Gehring U, Tamburic L, Sbihi H, Davies HW, Brauer M (2014) Impact of noise and air pollution on pregnancy outcomes. Epidemiology 25(3):351–358. https://doi.org/10.1097/EDE.0000000000000073
Hamilton TL, Phaneuf DJ (2015) An integrated model of regional and local residential sorting with application to air quality. J Environ Econ Manag 74(Supplement C):71–93. https://doi.org/10.1016/j.jeem.2015.08.001
Hinkle SN, Albert PS, Mendola P, Sjaarda LA, Yeung E, Boghossian NS, Laughon SK (2014) The association between parity and birth weight in a longitudinal consecutive pregnancy cohort. Paediatr Perinat Epidemiol 28(2):106–115. https://doi.org/10.1111/ppe.12099
Hu S, Fruin S, Kozawa K, Mara S, Paulson SE, Winer AM (2009) A wide area of air pollutant impact downwind of a freeway during pre-sunrise hours. Atmos Environ Oxf Engl 43(16):2541–2549. https://doi.org/10.1016/j.atmosenv.2009.02.033
Jans J, Johansson P, Nilsson JP (2018) Economic status, air quality, and child health: evidence from inversion episodes. J Health Econ 61:220–232. https://doi.org/10.1016/j.jhealeco.2018.08.002
Jerrett M, Arain A, Kanaroglou P, Beckerman B, Potoglou D, Sahsuvaroglu T, Morrison J, Giovis C (2005) A review and evaluation of intraurban air pollution exposure models. J Expo Anal Environ Epidemiol 15(2):185–204. https://doi.org/10.1038/sj.jea.7500388
Klaiber AH, Phaneuf DJ (2010) Valuing open space in a residential sorting model of the Twin Cities. J Environ Econ Manag 60(2):57–77
Knittel CR, Miller DL, Sanders NJ (2015) Caution, drivers! Children present: traffic, pollution, and infant health. Rev Econ Stat 98(2):350–366. https://doi.org/10.1162/REST_a_00548
Knittel CR, Sandler R (2013) The welfare impact of indirect pigouvian taxation: evidence from transportation (Working Paper No. 18849). National Bureau of Economic Research. https://doi.org/10.3386/w18849
McFadden D (1977) Modelling the choice of residential location (Cowles Foundation Discussion Paper No. 477). Cowles Foundation for Research in Economics, Yale University. http://econpapers.repec.org/paper/cwlcwldpp/477.htm
Mike Maciag (2015) Gentrification in America Report. Retrieved August 3, 2017, from http://www.governing.com/gov-data/gentrification-in-cities-governing-report.html
Moretti E, Neidell M (2009) Pollution, health, and avoidance behavior: evidence from the ports of Los Angeles (Working Paper No. 14939). National Bureau of Economic Research. https://doi.org/10.3386/w14939
Neidell M (2008) Information, avoidance behavior, and health: the effect of ozone on asthma hospitalizations (SSRN Scholarly Paper ID 1190358). Social Science Research Network. https://papers.ssrn.com/abstract=1190358
Nieuwenhuijsen MJ, Ristovska G, Dadvand P (2017) WHO environmental noise guidelines for the european region: a systematic review on environmental noise and adverse birth outcomes. Int J Environ Res Public Health. https://doi.org/10.3390/ijerph14101252
Oregon Total Gasoline Through Company Outlets Price by All Sellers (Dollars per Gallon). (n.d.). Retrieved November 10, 2017, from https://www.eia.gov/dnav/pet/hist/LeafHandler.ashx?n=PET&s=EMA_EPM0_PTC_SOR_DPG&f=A
Parmeter CF, Pope JC (2012) Quasi-experiments and hedonic property value methods (No. 2012-7; Working Papers). University of Miami, Department of Economics. https://ideas.repec.org/p/mia/wpaper/2012-7.html
Pinkerton KE, Joad JP (2000) The mammalian respiratory system and critical windows of exposure for children’s health. Environ Health Perspect 108(Suppl 3):457–462
Poverty in Oregon in Six Charts—Oregon Center for Public Policy. (n.d.). Retrieved July 2, 2020, from https://www.ocpp.org/2015/10/22/fs20151022-poverty-oregon-charts/
Ransom MR, Iii CAP (1995) External health costs of a steel mill. Contemp Econ Policy 13(2):86–97. https://doi.org/10.1111/j.1465-7287.1995.tb00745.x
Behmer TK, Foster L, Henry J, Woghiren-Akinnifesi E, Yip F (2013) Residential proximity to major highways—the United States, 2010. Retrieved July 8, 2020, from https://www.cdc.gov/mmwr/preview/mmwrhtml/su6203a8.htm
Smith KL, Peshkin D, Wolters A, Krstulovich J, Moulthrop J, Alvarado C, Transportation Research Board, Strategic Highway Research Program Renewal Focus Area, and Transportation Research Board (2011) Guidelines for the preservation of high-traffic-volume roadways. National Academies Press. https://doi.org/10.17226/14487
Smith VK, Huang J-C (1995) Can markets value air quality? A meta-analysis of hedonic property value models. J Polit Econ 103(1):209–227
Stansfeld SA (2015) Noise effects on health in the context of air pollution exposure. Int J Environ Res Public Health 12(10):12735–12760. https://doi.org/10.3390/ijerph121012735
Stone EA, Wu J, Alig R (2015) Urban green space and vibrant communities: exploring the linkage in the Portland Vancouver area. Gen. Tech. Rep. PNW-GTR-905. Portland, OR: U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station. 43 p., 905. https://doi.org/10.2737/PNW-GTR-905
Stuart EA (2010) Matching methods for causal inference: a review and a look forward. Stat Sci Rev J Inst Math Stat 25(1):1–21. https://doi.org/10.1214/09-STS313
Tiebout CM (1956) A pure theory of local expenditures. J Polit Econ 64. http://econpapers.repec.org/article/ucpjpolec/v_3a64_3ay_3a1956_3ap_3a416.htm
Westhoff F (1977) Existence of equilibria in economies with a local public good. J Econ Theory 14(1):84–112. https://doi.org/10.1016/0022-0531(77)90086-2
WHO Burden of disease from environmental noise—Quantification of healthy life years lost in Europe. (n.d.). WHO. Retrieved September 11, 2019, from https://www.who.int/quantifying_ehimpacts/publications/e94888/en/
Wilcox MA, Chang AM, Johnson IR (1996) The effects of parity on birthweight using successive pregnancies. Acta Obstet Gynecol Scand 75(5):459–453
Yang M, Chou S-Y (2018) The impact of environmental regulation on fetal health: evidence from the shutdown of a coal-fired power plant located upwind of New Jersey. J Environ Econ Manag 89:94–118. https://doi.org/10.1016/j.jeem.2017.11.005
Zdravkovic T, Genbacev O, McMaster MT, Fisher SJ (2005) The adverse effects of maternal smoking on the human placenta: a review. Placenta 26(Suppl A):S81-86. https://doi.org/10.1016/j.placenta.2005.02.003
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Figs. 5, 6 and Tables 6, 7, 8, 9, 10.

Density distribution of propensity score before and after matching (traffic-related pollution exposure). Notes: This figure shows the density distribution of the propensity score for treatment and control groups before and after matching. It indicates that the common support condition is met, so that balance greatly improves after matching

A hypothetical example of how a neighborhood’s income distribution is affected by sorting response to a reduction in traffic-related pollution from TRP1 to TRP2. Notes: This figure illustrates our hypothesis of the link between a reduction in traffic pollution exposure and neighborhood income distributions. If individuals sort in response to a localized pollution change (from traffic pollution exposure 1 to traffic pollution exposure 2), the corresponding housing price adjustment implies a change in the localized income distribution from income distribution 1 to distribution 2. This in turn alters the estimated neighborhood health impacts of the pollution change, since the treatment effect of traffic pollution exposure in the health model depends on income
Rights and permissions
About this article

Cite this article
Long, D., Lewis, D. & Langpap, C. Negative Traffic Externalities and Infant Health: The Role of Income Heterogeneity and Residential Sorting. Environ Resource Econ 80, 637–674 (2021). https://doi.org/10.1007/s10640-021-00601-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10640-021-00601-w